rubix / sentiment
一个使用多层前馈神经网络进行文本情感分类的项目示例,使用来自IMDB的25,000条电影评论进行训练。
Requires
- php: >=7.4
- rubix/ml: ^2.2
README
这是一个用于文本情感分类的多层前馈神经网络,使用来自IMDB电影评论网站上的25,000条电影评论进行训练。数据集还提供了另外25,000个样本,我们使用这些样本在训练后测试模型。此示例项目通过使用称为多层感知器的神经网络分类器,展示了Rubix ML中的文本特征表示和深度学习。
- 难度:困难
- 训练时间:数小时
安装
使用 Composer 在本地克隆项目
$ composer create-project rubix/sentiment
注意:由于数据集较大,安装可能需要比平时更长的时间。
要求
- PHP 7.4 或更高版本
- 16G或更多的系统内存
推荐
- Tensor 扩展 以加快训练和推理
教程
简介
我们的目标是使用机器学习预测一组英文文本的情感(正面或负面)。有时我们将其称为自然语言处理(NLP),因为它涉及机器理解语言。提供给我们数据集包含25,000个训练样本和25,000个测试样本,每个样本都包含一篇IMDB网站上关于电影的英文评论。样本根据评论者给电影的评分(1-10分)被标记为正面或负面。从这里开始,我们将使用IMDB数据集训练一个多层神经网络,以预测我们展示的任何英文文本的情感。
示例
"一个对猪有非自然感情的男人的故事。开头场景是一个荒诞喜剧的绝佳例子。一个正式的管弦乐观众被它歌手的疯狂吟唱变成了一个疯狂、暴力的暴民。不幸的是,整个故事都是荒诞的,没有一般性的叙事,最终让人感到难以接受。……"
提取数据
样本以单独的.txt文件提供,并根据标签组织到positive和negative文件夹中。我们将使用PHP内置的glob()函数遍历每个文件夹中的所有文本文件,并将它们的内容添加到样本数组中。我们还将添加相应的positive和negative标签到它们自己的数组中。
注意:此示例的源代码可以在项目根目录中的train.php文件中找到。
$samples = $labels = []; foreach (['positive', 'negative'] as $label) { foreach (glob("train/$label/*.txt") as $file) { $samples[] = [file_get_contents($file)]; $labels[] = $label; } }
现在,我们可以使用导入的样本和标签创建一个新的Labeled数据集对象。
use Rubix\ML\Datasets\Labeled; $dataset = new Labeled($samples, $labels);
数据集准备
神经网络计算非线性连续函数,因此需要连续特征作为输入。然而,我们收到的IMDB数据集中的样本是以原始文本格式存在的。因此,在训练之前,我们需要将这些文本块转换为连续特征。我们将使用词袋技术,该技术使用固定词汇表生成长稀疏的词频向量。准备输入数据集以供网络使用所需的整个转换系列可以在转换器中实现。
首先,我们将使用文本规范器将所有字符转换为小写,以便每个单词只由一个标记表示。然后,词频向量器从原始文本创建固定长度的词频连续特征向量,而TF-IDF 转换器对这些计数应用加权方案。最后,Z 缩放标准器将TF-IDF加权的计数中心化并缩放样本矩阵,以使其具有0均值和单位方差。这一最后步骤将有助于神经网络更快地收敛。
词频向量器是一种词袋特征提取器,它使用固定词汇量和词频来量化文档中出现的单词。我们选择将词汇量的大小限制为至少出现在2个不同文档中但不超过10,000个文档的10,000个最频繁的单词。这样,我们限制了进入训练集的噪声词的数量。
另一种常见的文本特征表示是TF-IDF值,它将词频向量器中的词频(TF)与逆文档频率(IDF)相乘。IDFs可以解释为词在训练语料库中的重要性。具体来说,对稀有词给予更高的权重。
实例化学习器
接下来,我们将定义神经网络的架构并实例化多层感知器分类器。该网络使用5个隐藏层,包括一个密集层神经元,后面跟一个非线性激活层和一个可选的批归一化层用于归一化激活。前3个隐藏层使用漏激活ReLU激活函数,而最后2个利用了Leaky ReLU的可训练形式,称为PReLU(参数化ReLU)。这种泄漏比标准整流的优势在于,即使在神经元未激活的情况下,也允许神经元通过在反向传播期间允许一个小梯度通过来学习。我们发现这种架构对这个问题的效果相当不错,但请随意进行自己的实验。
use Rubix\ML\PersistentModel; use Rubix\ML\Pipeline; use Rubix\ML\Transformers\TextNormalizer; use Rubix\ML\Transformers\WordCountVectorizer; use Rubix\ML\Transformers\TfIdfTransformer; use Rubix\ML\Transformers\ZScaleStandardizer; use Rubix\ML\Other\Tokenizers\NGram; use Rubix\ML\Classifiers\MultilayerPerceptron; use Rubix\ML\NeuralNet\Layers\Dense; use Rubix\ML\NeuralNet\Layers\PReLU; use Rubix\ML\NeuralNet\Layers\Activation; use Rubix\ML\NeuralNet\Layers\BatchNorm; use Rubix\ML\NeuralNet\ActivationFunctions\LeakyReLU; use Rubix\ML\NeuralNet\Optimizers\AdaMax; use Rubix\ML\Persisters\Filesystem; $estimator = new PersistentModel( new Pipeline([ new TextNormalizer(), new WordCountVectorizer(10000, 2, 0.4, new NGram(1, 2)), new TfIdfTransformer(), new ZScaleStandardizer(), ], new MultilayerPerceptron([ new Dense(100), new Activation(new LeakyReLU()), new Dense(100), new Activation(new LeakyReLU()), new Dense(100, 0.0, false), new BatchNorm(), new Activation(new LeakyReLU()), new Dense(50), new PReLU(), new Dense(50), new PReLU(), ], 256, new AdaMax(0.0001))), new Filesystem('sentiment.rbx', true) );
我们将选择256个样本的批次大小,并使用AdaMax优化器进行网络参数更新。AdaMax基于Adam算法,但更擅长处理稀疏更新。在设置优化器的学习率时,需要注意的是,学习率太低会导致网络学习缓慢,而学习率太高则会阻止网络学习。对于这个问题,全局学习率0.0001似乎效果不错。
最后,我们将整个估计器封装在一个持久化模型包装器中,这样我们就可以在其他脚本中稍后保存和加载它。文件系统持久化器告诉包装器从磁盘上的路径保存和加载序列化模型数据。将历史参数设置为true告诉持久化器保存过去保存的历史记录。
训练
现在,您可以通过将之前实例化的训练数据集作为参数传递给学习器的train()方法来启动训练过程。
$estimator->train($dataset);
验证分数和损失
在训练过程中,学习器将记录每个迭代或时期的验证分数和训练损失。验证分数使用默认的F Beta指标在训练集的一个保留部分(称为验证集)上计算。相反,训练损失是成本函数(在这种情况下是交叉熵损失)在训练集中剩余样本上的值。我们可以通过绘制这些指标来可视化训练进度。要输出分数和损失,您可以调用额外的steps()方法,并将结果迭代器传递给如CSV之类的可写提取器。
use Rubix\ML\Extractors\CSV; $extractor = new CSV('progress.csv', true); $extractor->export($estimator->steps());
以下是验证分数和训练损失绘制出的示例。验证分数应该随着每个时期的进行而提高,同时损失降低。您可以通过将progress.csv文件导入您的绘图应用程序来生成自己的绘图。
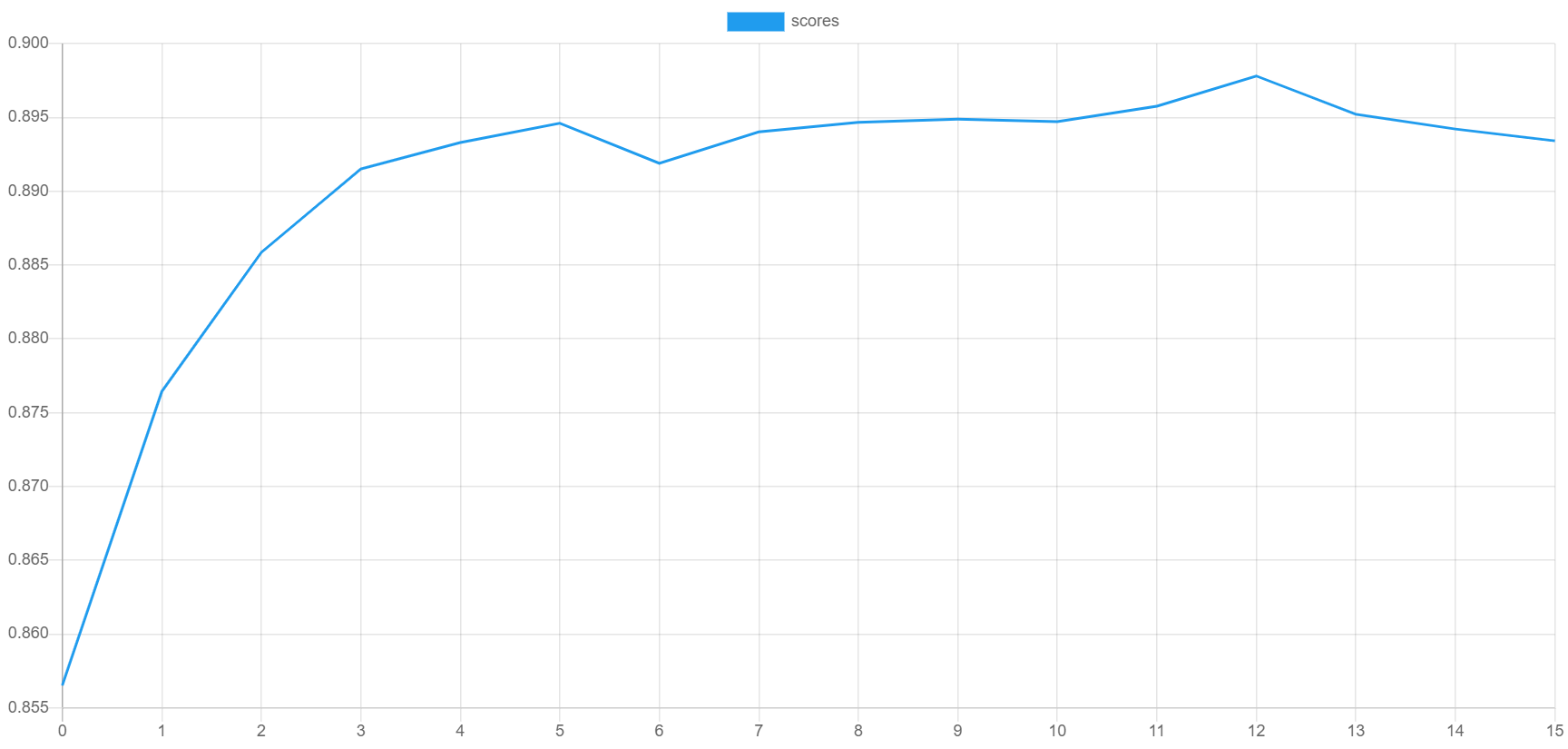
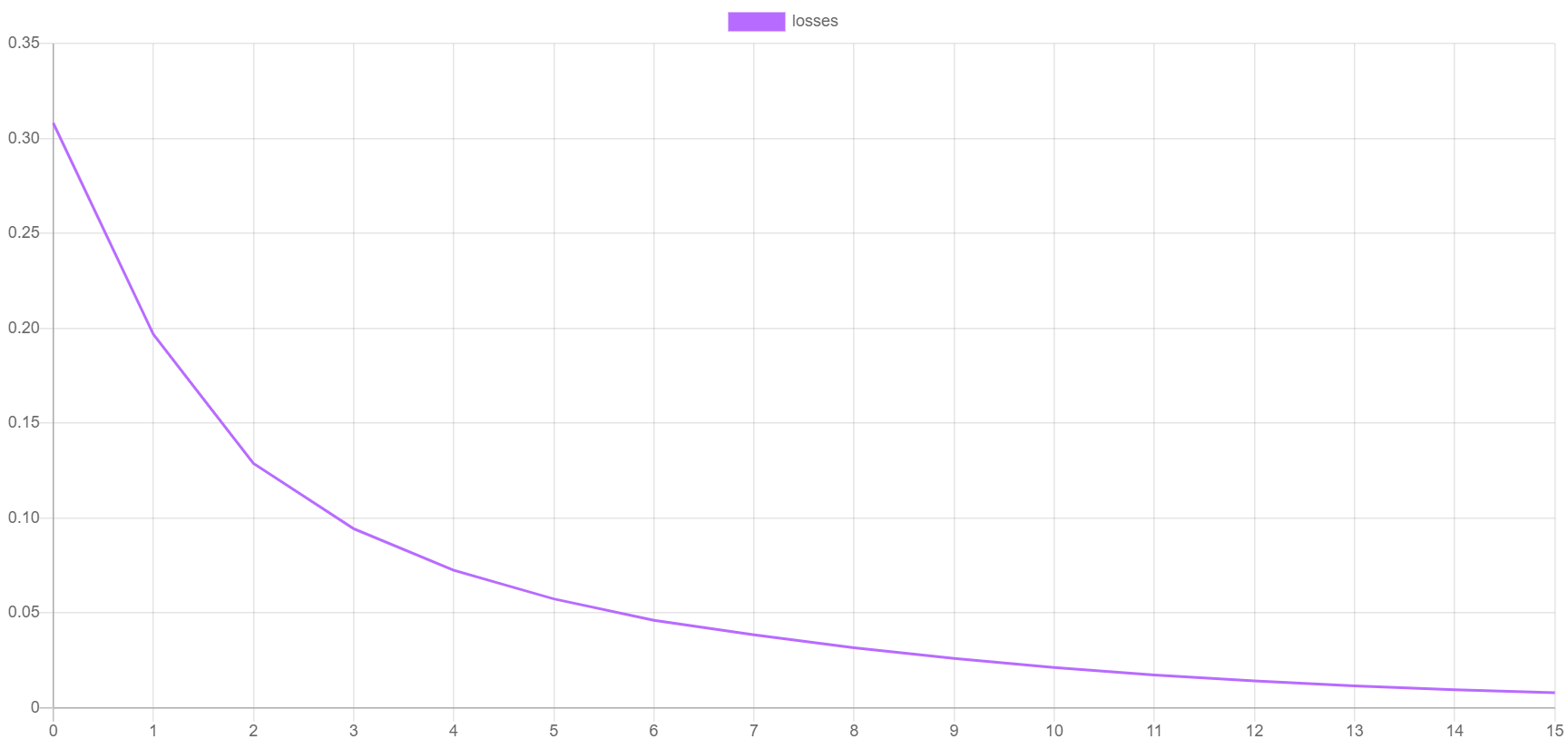
保存
最后,我们保存模型,以便我们可以在验证和预测脚本中稍后加载它。
$estimator->save();
现在您可以从命令行运行训练脚本。
$ php train.php
交叉验证
为了测试训练网络的泛化性能,我们将使用提供的测试样本来生成预测,然后使用交叉验证报告分析它们与它们的真实标签相比的情况。请注意,我们不使用任何训练数据进行交叉验证,因为我们想测试模型从未见过的样本。
注意:此示例的源代码可以在项目根目录中的validate.php文件中找到。
我们首先像处理训练样本一样从test文件夹导入测试样本。
$samples = $labels = []; foreach (['positive', 'negative'] as $label) { foreach (glob("test/$label/*.txt") as $file) { $samples[] = [file_get_contents($file)]; $labels[] = $label; } }
然后,使用build()方法将样本和标签加载到Labeled数据集对象中,随机化顺序,并将前10,000行放入新的数据集对象中。
use Rubix\ML\Datasets\Labeled; $dataset = Labeled::build($samples, $labels)->randomize()->take(10000);
接下来,我们将使用持久化模型包装器加载我们之前训练的网络。
use Rubix\ML\PersistentModel; use Rubix\ML\Persisters\Filesystem; $estimator = PersistentModel::load(new Filesystem('sentiment.rbx'));
现在,我们可以使用估计器在测试集上做出预测。估计器的predict()方法接受一个数据集作为输入,并返回一个预测数组。
$predictions = $estimator->predict($dataset);
我们将生成的交叉验证报告实际上是由两个报告组合而成的 - 多类别分解 和 混淆矩阵。我们将每个报告封装在一个 综合报告 中,以一次生成两个报告。多类别分解将提供关于估计量在类别层面的性能的详细信息。混淆矩阵将通过将预测值分成一个 2 x 2 矩阵,让我们了解估计量混淆了哪些标签。
use Rubix\ML\CrossValidation\Reports\AggregateReport; use Rubix\ML\CrossValidation\Reports\ConfusionMatrix; use Rubix\ML\CrossValidation\Reports\MulticlassBreakdown; $report = new AggregateReport([ new MulticlassBreakdown(), new ConfusionMatrix(), ]);
要生成报告,请将测试集的预测值和标签传递给报告上的 generate() 方法。返回值是一个报告对象,可以输出到控制台。
$results = $report->generate($predictions, $dataset->labels()); echo $results;
我们还将使用文件系统持久化器将报告的副本保存到 JSON 文件中。
$results->toJSON()->saveTo(new Filesystem('report.json'));
现在我们可以从命令行执行验证脚本。
$ php validate.php
查看报告,看看模型的性能如何。根据下面的示例报告,我们的模型大约有 88% 的准确率。
[
{
"overall": {
"accuracy": 0.8756,
"accuracy_balanced": 0.8761875711932667,
"f1_score": 0.8751887769748257,
"precision": 0.8820119837481977,
"recall": 0.8761875711932667,
"specificity": 0.8761875711932667,
"negative_predictive_value": 0.8820119837481977,
"false_discovery_rate": 0.11798801625180227,
"miss_rate": 0.12381242880673332,
"fall_out": 0.12381242880673332,
"false_omission_rate": 0.11798801625180227,
"threat_score": 0.778148276032161,
"mcc": 0.7581771833363391,
"informedness": 0.7523751423865335,
"markedness": 0.7640239674963953,
"true_positives": 8756,
"true_negatives": 8756,
"false_positives": 1244,
"false_negatives": 1244,
"cardinality": 10000
},
"classes": {
"positive": {
"accuracy": 0.8756,
"accuracy_balanced": 0.8761875711932667,
"f1_score": 0.8680246127731805,
"precision": 0.9338050673362246,
"recall": 0.8109018830525273,
"specificity": 0.941473259334006,
"negative_predictive_value": 0.8302189001601709,
"false_discovery_rate": 0.06619493266377541,
"miss_rate": 0.1890981169474727,
"fall_out": 0.05852674066599395,
"false_omission_rate": 0.16978109983982914,
"threat_score": 0.7668228678537957,
"informedness": 0.7523751423865335,
"markedness": 0.7523751423865335,
"mcc": 0.7581771833363391,
"true_positives": 4091,
"true_negatives": 4665,
"false_positives": 290,
"false_negatives": 954,
"cardinality": 5045,
"proportion": 0.5045
},
"negative": {
"accuracy": 0.8756,
"accuracy_balanced": 0.8761875711932667,
"f1_score": 0.8823529411764707,
"precision": 0.8302189001601709,
"recall": 0.941473259334006,
"specificity": 0.8109018830525273,
"negative_predictive_value": 0.9338050673362246,
"false_discovery_rate": 0.16978109983982914,
"miss_rate": 0.05852674066599395,
"fall_out": 0.1890981169474727,
"false_omission_rate": 0.06619493266377541,
"threat_score": 0.7894736842105263,
"informedness": 0.7523751423865335,
"markedness": 0.7523751423865335,
"mcc": 0.7581771833363391,
"true_positives": 4665,
"true_negatives": 4091,
"false_positives": 954,
"false_negatives": 290,
"cardinality": 4955,
"proportion": 0.4955
}
}
},
{
"positive": {
"positive": 4091,
"negative": 290
},
"negative": {
"positive": 954,
"negative": 4665
}
}
]
做得好!现在我们可以对新的数据进行一些预测了。
预测单个样本
现在我们已经对我们的模型有信心了,让我们编写一个简单的脚本,它从终端接收一些文本输入,并使用我们刚刚训练的估计量输出情感预测。
注意:本例的源代码可在项目根目录中的 predict.php 文件中找到。
首先,使用 Persistent Model 元估计器的静态 load() 方法以及指向包含序列化模型数据的文件的文件系统持久化器从存储中加载模型。
use Rubix\ML\PersistentModel; use Rubix\ML\Persisters\Filesystem; $estimator = PersistentModel::load(new Filesystem('sentiment.rbx'));
接下来,我们将使用内置的 PHP 函数 readline() 提示用户输入一些文本,并将其存储在一个变量中。
while (empty($text)) $text = readline("Enter some text to analyze:\n");
要对刚才输入的文本进行预测,请在估计量上调用 predictSample() 方法,并传入一个包含与训练集相同顺序的特征值的数组。由于我们在这个情况下只有一个输入特征,所以顺序很简单!
$prediction = $estimator->predictSample([$text]); echo "The sentiment is: $prediction" . PHP_EOL;
要运行预测脚本,请在命令行中输入以下内容。
php predict.php
输出
Enter some text to analyze: Rubix ML is really great The sentiment is: positive
下一步
祝贺您完成 Rubix ML 中使用多层感知器进行文本情感分类的教程。我们建议您在自己的网络架构和超参数上尝试,以了解它们如何影响模型。一般来说,增加更多神经元和层可以提高性能,但训练时间可能会相应变长。此外,更大的词汇量也可能在增加训练和推理期间的计算成本的同时提高准确率。
原始数据集
请参阅 DATASET_README。有关数据集的评论或问题,请联系 Andrew Maas。
参考文献
- Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. (2011). Learning Word Vectors for Sentiment Analysis. The 49th Annual Meeting of the Association for Computational Linguistics (ACL 2011).
许可证
代码遵循 MIT 许可证,教程遵循 CC BY-NC 4.0 许可证。