rubix / mnist
使用前馈神经网络和MNIST数据集(包含70,000个由人类标注的手写数字)进行手写数字识别。
Requires
- php: >=7.4
- ext-gd: *
- rubix/ml: ^2.0
README
《MNIST》数据集是一组70,000张由人类标注的28 x 28灰度图像,代表单个手写数字。它是从NIST(美国国家标准与技术研究院)提供的更大数据集的一个子集。在本教程中,您将使用MNIST数据集训练多层神经网络来创建自己的手写数字识别器。
- 难度:难
- 训练时间:数小时
安装
使用Composer在本地克隆项目
$ composer create-project rubix/mnist
注意:由于数据集较大,安装可能需要比平时更长的时间。
要求
推荐
- Tensor扩展以实现更快的训练和推理
- 3GB或更多系统内存
教程
简介
在本教程中,我们将使用Rubix ML训练一个名为多层感知器的深度学习模型,以识别手写数字。对于这个问题,分类器需要能够学习线条、边缘、角落以及它们的组合,以便在图像中区分数字。下面的图显示了在MNIST数据集上训练的神经网络某一层的特征快照。该图表明,在网络中的每一层,网络都会构建一个更详细的训练数据表示,直到输出层的Softmax层使得数字可以被区分。

注意:该示例的源代码可以在项目根目录下的train.php文件中找到。
提取数据
MNIST数据集以60,000个训练图像和10,000个测试图像的形式提供,这些图像组织在子文件夹中,文件夹名是赋予样本的人类标注标签。我们将使用GD库中的imagecreatefrompng()函数将图像加载到脚本中,并根据它们所在的子文件夹为它们分配标签。
$samples = $labels = []; for ($label = 0; $label < 10; $label++) { foreach (glob("training/$label/*.png") as $file) { $samples[] = [imagecreatefrompng($file)]; $labels[] = "#$label"; } }
然后,我们可以使用标准构造函数从样本和标签实例化一个新的Labeled数据集对象。
use Rubix\ML\Datasets\Labeled; $dataset = new Labeled($samples, $labels);
数据集准备
我们将使用一个Pipeline来将数据集转换为适合我们的学习器的正确格式。我们知道MNIST数据集中每个样本图像的大小是28 x 28像素,但为了确保未来的样本始终具有正确的输入大小,我们将添加一个Image Resizer。然后,为了将图像转换为原始像素数据,我们将使用Image Vectorizer,它从图像中提取连续的原始颜色通道值。由于样本图像是黑白的,我们只需要每个像素使用一个颜色通道。在pipeline的末尾,我们将使用Z Scale Standardizer对数据集进行居中和缩放,以帮助加快神经网络的收敛速度。
实例化学习器
现在,我们将实例化我们的Multilayer Perceptron分类器。让我们考虑一个适合MNIST问题的神经网络架构,它由3组Dense神经元层组成,后面跟着一个ReLU激活层,然后是一个轻微的Dropout层作为正则化器。输出层添加了一个额外的神经元层,并使用Softmax激活,使这个特定的网络架构有4层深。
接下来,我们将批量大小设置为256。批量大小是每次通过网络发送的样本数量。我们还将指定一个优化器和学习率,这决定了梯度下降算法的更新步骤。使用Adam优化器结合了Momentum和RMS Prop来更新其更新,通常比标准的stochastic梯度下降收敛得更快。它使用全局学习率来控制步骤的大小,我们将将其设置为0.0001作为此示例。
use Rubix\ML\PersistentModel; use Rubix\ML\Pipeline; use Rubix\ML\Transformers\ImageResizer; use Rubix\ML\Transformers\ImageVectorizer; use Rubix\ML\Transformers\ZScaleStandardizer; use Rubix\ML\Classifiers\MultiLayerPerceptron; use Rubix\ML\NeuralNet\Layers\Dense; use Rubix\ML\NeuralNet\Layers\Dropout; use Rubix\ML\NeuralNet\Layers\Activation; use Rubix\ML\NeuralNet\ActivationFunctions\ReLU; use Rubix\ML\NeuralNet\Optimizers\Adam; use Rubix\ML\Persisters\Filesystem; $estimator = new PersistentModel( new Pipeline([ new ImageResizer(28, 28), new ImageVectorizer(true), new ZScaleStandardizer(), ], new MultiLayerPerceptron([ new Dense(100), new Activation(new ReLU()), new Dropout(0.2), new Dense(100), new Activation(new ReLU()), new Dropout(0.2), new Dense(100), new Activation(new ReLU()), new Dropout(0.2), ], 256, new Adam(0.0001))), new Filesystem('mnist.rbx', true) );
为了使我们能够从存储中保存和加载模型,我们将使用Persistent Model元估计器包装整个pipeline。Persistent Model在基础估计器的方法之上提供了额外的save()和load()方法。它需要一个Persister对象来告诉它模型要存储的位置。对于我们的目的,我们将使用Filesystem persister,它接受磁盘上模型文件的路径。将历史模式设置为true意味着持久化器将跟踪每次保存的历史。
训练
要开始训练神经网络,请对Estimator实例调用具有训练集作为参数的train()方法。
$estimator->train($dataset);
验证分数和损失
我们可以通过在训练后输出损失函数和验证指标的值来可视化每个阶段的训练进度。steps()方法将输出一个包含默认Cross Entropy损失函数值的迭代器,而scores()方法将返回F Beta度量的一组分数。
注意: 您可以通过将它们设置为学习器的超参数来更改成本函数和验证度量。
use Rubix\ML\Extractors\CSV; $extractor = new CSV('progress.csv', true); $extractor->export($estimator->steps());
然后,我们可以使用我们最喜欢的绘图软件(例如 Tableau 或 Excel)绘制这些值。如果一切顺利,随着验证分数的提高,损失值应该下降。由于快照的存在,验证分数最高且损失最低的epoch点是网络参数值被用于最终模型的点。这通过有效地重新学习数据集中的噪声来防止网络过拟合训练数据。
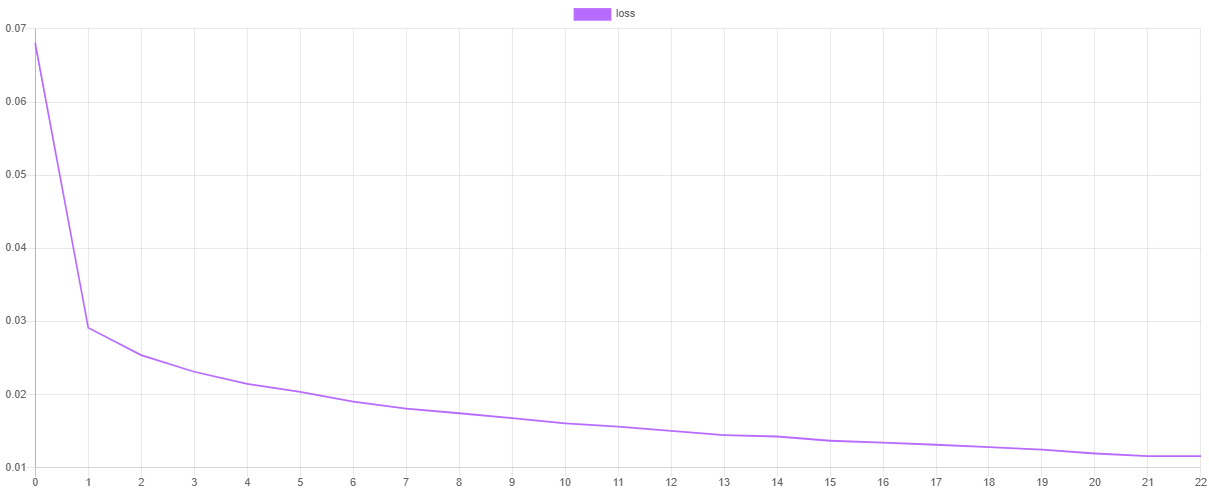
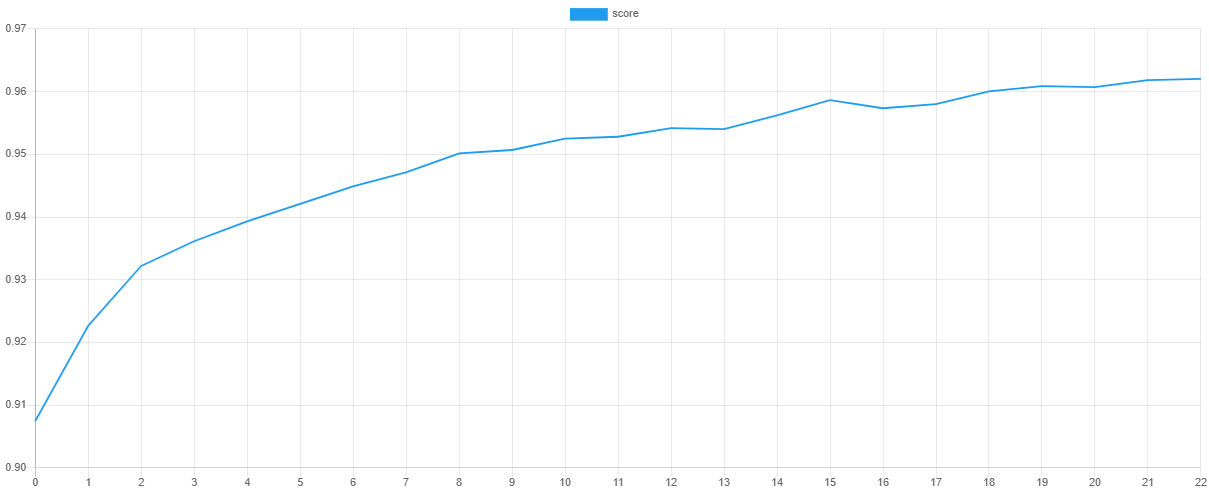
保存
我们可以通过调用持久化模型包装器提供的save()方法来保存训练好的网络。该模型将以紧凑的序列化格式(例如 原生 PHP序列化格式或Igbinary)保存。
$estimator->save();
现在我们可以从命令行执行训练脚本了。
$ php train.php
交叉验证
交叉验证是一种评估估计器如何将训练推广到独立数据集的技术。目标是识别会导致模型在新未见数据上表现不佳的问题,例如欠拟合、过拟合或选择偏差。
幸运的是,MNIST数据集包含额外的10,000个标记图像,我们可以使用这些图像来测试模型。由于我们尚未使用这些样本来训练网络,我们可以使用它们来测试模型的一般化性能。首先,我们将从testing文件夹中提取测试样本和标签到一个标记数据集对象中。
use Rubix\ML\Datasets\Labeled; $samples = $labels = []; for ($label = 0; $label < 10; $label++) { foreach (glob("testing/$label/*.png") as $file) { $samples[] = [imagecreatefrompng($file)]; $labels[] = "#$label"; } } $dataset = new Labeled($samples, $labels);
从存储中加载模型
在我们的训练脚本中,我们确保在退出之前保存了模型。在我们的验证脚本中,我们将从存储中加载训练好的模型,并使用它对测试集进行预测。静态的load()方法在持久化模型上接受一个指向存储中模型的持久化器对象作为其唯一参数,并返回加载的估计器实例。
use Rubix\ML\PersistentModel; use Rubix\ML\Persisters\Filesystem; $estimator = PersistentModel::load(new Filesystem('mnist.rbx'));
进行预测
现在我们可以使用估计器对测试集进行预测。predict()方法接受一个数据集作为输入,并返回一个预测数组。
$predictions = $estimator->predict($dataset);
生成报告
我们将生成的交叉验证报告实际上是两个报告的组合 - 多类分解 和 混淆矩阵。我们将每个报告包装在一个汇总报告中,以在它们自己的键下同时生成两个报告。
use Rubix\ML\CrossValidation\Reports\AggregateReport; use Rubix\ML\CrossValidation\Reports\ConfusionMatrix; use Rubix\ML\CrossValidation\Reports\MulticlassBreakdown; $report = new AggregateReport([ 'breakdown' => new MulticlassBreakdown(), 'matrix' => new ConfusionMatrix(), ]);
要生成报告,将预测以及测试集中的标签传递给报告上的generate()方法。
$results = $report->generate($predictions, $dataset->labels()); echo $results;
现在我们可以从命令行运行验证脚本了。
$ php validate.php
下面是一个示例报告的摘录。如您所见,我们的模型在测试集上实现了99%的准确率。
{
"breakdown": {
"overall": {
"accuracy": 0.9936867061871887,
"accuracy_balanced": 0.9827299300164292,
"f1_score": 0.9690024869169903,
"precision": 0.9690931602689105,
"recall": 0.9689771553342812,
"specificity": 0.9964827046985771,
"negative_predictive_value": 0.9964864183831919,
"false_discovery_rate": 0.030906839731089673,
"miss_rate": 0.031022844665718752,
"fall_out": 0.003517295301422896,
"false_omission_rate": 0.0035135816168081367,
"threat_score": 0.939978395041131,
"mcc": 0.9655069498416134,
"informedness": 0.9654598600328583,
"markedness": 0.9655795786521022,
"true_positives": 9692,
"true_negatives": 87228,
"false_positives": 308,
"false_negatives": 308,
"cardinality": 10000
},
"classes": {
"#0": {
"accuracy": 0.9961969369924967,
"accuracy_balanced": 0.9924488163078695,
"f1_score": 0.9812468322351747,
"precision": 0.9748237663645518,
"recall": 0.9877551020408163,
"specificity": 0.9971425305749229,
"negative_predictive_value": 0.9986263736263736,
"false_discovery_rate": 0.025176233635448186,
"miss_rate": 0.01224489795918371,
"fall_out": 0.0028574694250771415,
"false_omission_rate": 0.0013736263736263687,
"threat_score": 0.96318407960199,
"informedness": 0.984897632615739,
"markedness": 0.984897632615739,
"mcc": 0.9791571571236778,
"true_positives": 968,
"true_negatives": 8724,
"false_positives": 25,
"false_negatives": 12,
"cardinality": 980,
"proportion": 0.098
},
"#2": {
"accuracy": 0.9917118592039292,
"accuracy_balanced": 0.9774202967570631,
"f1_score": 0.960698689956332,
"precision": 0.9620991253644315,
"recall": 0.9593023255813954,
"specificity": 0.9955382679327308,
"negative_predictive_value": 0.9951967063129002,
"false_discovery_rate": 0.03790087463556846,
"miss_rate": 0.04069767441860461,
"fall_out": 0.004461732067269186,
"false_omission_rate": 0.004803293687099752,
"threat_score": 0.9243697478991597,
"informedness": 0.9548405935141262,
"markedness": 0.9548405935141262,
"mcc": 0.9560674244463004,
"true_positives": 990,
"true_negatives": 8702,
"false_positives": 39,
"false_negatives": 42,
"cardinality": 1032,
"proportion": 0.1032
},
}
},
"matrix": {
"#0": {
"#0": 968,
"#5": 2,
"#2": 5,
"#9": 3,
"#8": 3,
"#6": 8,
"#7": 2,
"#3": 1,
"#1": 0,
"#4": 1
},
"#5": {
"#0": 2,
"#5": 859,
"#2": 3,
"#9": 7,
"#8": 7,
"#6": 5,
"#7": 0,
"#3": 6,
"#1": 1,
"#4": 0
},
}
}
下一步
祝贺您完成 Rubix ML 中的 MNIST 手写数字识别教程。我们强烈建议浏览文档,以更好地了解神经网络子系统可以做什么。深度学习还适用于解决哪些其他问题?
原始数据集
Yann LeCun,纽约大学柯朗数学科学研究所教授,邮箱:yann 'at' cs.nyu.edu
Corinna Cortes,谷歌实验室研究科学家,纽约,邮箱:corinna 'at' google.com
参考文献
- Y. LeCun 等人(1998)。基于梯度的学习在文档识别中的应用。
许可协议
代码采用MIT许可,教程采用CC BY-NC 4.0许可。