rubix / iris
Rubix ML 中使用著名的 Iris 数据集和 K 最近邻分类器对机器学习进行介绍。
Requires
- php: >=7.4
- rubix/ml: ^2.0
This package is auto-updated.
Last update: 2024-09-21 01:22:12 UTC
README
本教程轻量级介绍如何在 Rubix ML 中使用著名的 Iris 数据集 和 K 最近邻算法进行机器学习。在本教程结束时,您将了解如何构建项目、实例化学习者并在一些测试数据上对其进行训练。
- 难度:简单
- 训练时间:少于一分钟
安装
使用 Composer 在本地克隆项目
$ composer create-project rubix/iris
要求
- PHP 7.4 或更高版本
教程
简介
Iris 数据集包含三种 Iris 花品种(Iris setosa、Iris virginica 和 Iris versicolor)的 50 个样本。每个样本由 4 个测量值或 特征 组成 - 萼片长度、萼片宽度、花瓣长度和花瓣宽度。我们的目标是训练一个 K 最近邻 (KNN) 分类器,使用 Iris 数据集确定未知测试样本的 Iris 花品种。让我们开始吧!

提取数据
第一步是将 Iris 数据集从项目文件夹中的 dataset.ndjson 文件提取到我们的训练脚本中。您会注意到我们还将 Iris 数据集提供为 CSV(逗号分隔值)格式,这是为了方便您在您最喜欢的电子表格软件中查看数据集。为了实例化一个新的 Labeled 数据集对象,我们将传递一个指向项目文件夹中数据集文件的 NDJSON 提取器到 fromIterator() 工厂方法。工厂使用数据表的最后一列作为标签,其余列作为样本特征的值。我们将这称为我们的 训练 集合。
注意:本示例的源代码可在项目根目录下的 train.php 文件中找到。
use Rubix\ML\Datasets\Labeled; use Rubix\ML\Extractors\NDJSON; $training = Labeled::fromIterator(new NDJSON('dataset.ndjson'));
接下来,我们将预留 10 个随机样本,稍后我们将使用这些样本进行一些示例预测并评估模型。数据集对象的 randomize() 方法将处理数据以确保随机性,而 take() 方法则从训练集中取出前 n 行并将其放入一个单独的数据集对象中。我们这样做是因为我们想在尚未训练的样本上测试模型。
$testing = $dataset->randomize()->take(10);
实例化学习者
接下来,我们将实例化K近邻分类器,并选择超参数k的值。超参数是构造函数参数,它们影响学习器在训练和推理过程中的行为。KNN是一种基于距离的算法,它从训练集中找到最接近的k个样本,并预测最常见标签。例如,如果我们选择k等于5,那么我们可能得到4个标签为 Iris setosa,1个标签为 Iris virginica。在这种情况下,估计器将预测Iris-setosa,因为这个标签最常见。要实例化学习器,请将超参数k的值传递给学习器的构造函数。有关KNN的附加超参数的更多信息,请参阅文档。
use Rubix\ML\Classifiers\KNearestNeighbors; $estimator = new KNearestNeighbors(5);
训练
现在,我们可以通过调用我们之前准备的训练集的train()方法来训练学习器。
$estimator->train($training);
进行预测
模型训练完成后,我们可以通过在测试集上调用predict()方法来使用测试数据进行预测。
$predictions = $estimator->predict($testing);
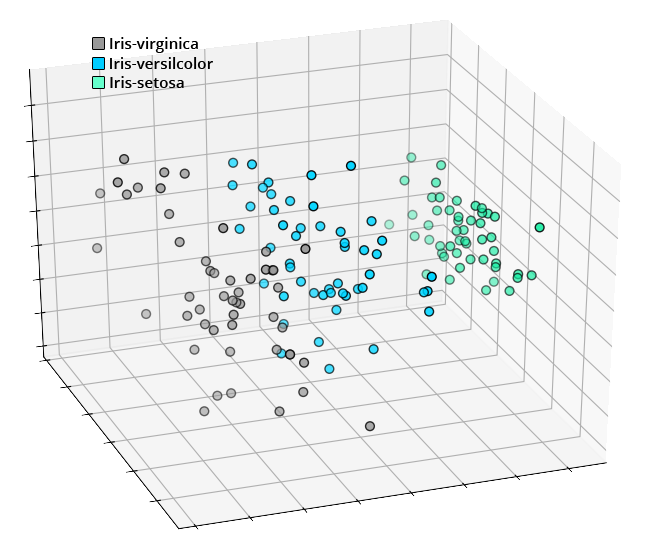
在推理过程中,KNN算法将样本的特征解释为空间坐标,并使用样本之间的距离来确定它已经看到的数据中最相似的样本。从下面的可视化中,我们可以看到每种Iris花种的特性形成了可以被K近邻算法学习的独特簇。
验证分数
我们可以通过比较训练期间生成的模型的预测与测试集中的真实标签来测试训练期间生成的模型。我们需要选择一个交叉验证度量来输出一个分数,我们将该分数解释为我们新训练估计器的泛化能力。《a href="https://docs.rubixml.com/latest/cross-validation/metrics/accuracy.html" rel="nofollow noindex noopener external ugc">准确度是一个简单的分类度量,其范围为0到1,计算为正确预测数与预测总数之比。为了获得准确度分数,将我们从模型中生成的预测以及测试集的标签传递给度量实例的score方法。
use Rubix\ML\CrossValidation\Metrics\Accuracy; $metric = new Accuracy(); $score = $metric->score($predictions, $testing->labels());
现在您可以从命令行运行训练脚本。
php train.php
下一步
恭喜您使用Iris数据集完成PHP中Rubix ML的机器学习入门。现在您可以开始自己的实验了。例如,您可能想尝试不同的k值,或者将默认的欧几里得距离核替换为其他核,如曼哈顿或闵可夫斯基。
原始数据集
创建者:Ronald Fisher 联系人:Michael Marshall 邮箱:(1) MARSHALL%PLU '@' io.arc.nasa.gov
参考文献
- R. A. Fisher. (1936). 多测量在分类问题中的应用。
- Dua, D. 和 Graff, C. (2019). UCI机器学习库 [http://archive.ics.uci.edu/ml]. 加利福尼亚州欧文,加州大学信息与计算机科学学院。
许可
代码采用MIT许可,教程采用CC BY-NC 4.0许可。