rubix / housing
一个使用梯度提升机预测Kaggle竞赛中房价的示例项目。
Requires
- php: >=7.4
- rubix/ml: ^2.0
README
这是一个使用梯度提升机(GBM)和Kaggle竞赛中的一个流行数据集来预测房价的Rubix ML示例项目。在本教程中,您将了解回归和分阶段累加的增强集成方法——梯度提升。在本教程结束时,您将能够提交自己的预测到Kaggle竞赛。
- 难度:中等
- 训练时间:分钟
来自Kaggle
让一个购房人描述他们的梦想家园,他们可能不会从地下室天花板的尺寸或靠近东西向铁路的近远开始。但这个游乐场竞赛的数据集证明,影响价格谈判的因素远不止卧室数量或白色栅栏。
这个竞赛提供了79个解释变量,描述了爱荷华州艾姆斯市几乎所有住宅的各个方面,挑战你预测每座房屋的最终价格。
安装
使用 Composer 在本地克隆项目
$ composer create-project rubix/housing
要求
- PHP 7.4 或更高版本
推荐
- Tensor扩展,用于更快的训练和推理
- 1G的系统内存或更多
教程
简介
Kaggle 是一个平台,您可以通过参与竞赛来测试您的数据科学技能。本教程旨在通过Kaggle房价挑战作为示例,引导您使用Rubix ML进行回归问题。我们有一个包含1,460个标记样本的训练集,我们将使用它来训练学习器,以及1,459个未标记样本来做出预测。每个样本包含多种分类和连续数据类型的异构混合。我们的目标是构建一个估计器,可以正确预测房屋的销售价格。我们将选择 梯度提升 作为我们的学习器,因为它提供了良好的性能,并且能够处理分类和连续特征。
注意:本示例的源代码可以在项目根目录中的 train.php 文件中找到。
提取数据
数据以两个单独的CSV文件的形式提供给我们 - dataset.csv,其中包含用于训练的标签,以及unknown.csv,其中不包含标签用于预测。每个特征列在CSV表头中以一个标题表示,我们将使用它来识别列,并使用我们的列选择器。列选择器允许我们在数据传输过程中选择和重新排列数据表的列。它包装了另一个迭代器对象,如内置的CSV提取器。在这种情况下,我们不需要数据集中的Id列,因为它与结果不相关,所以我们只指定所需的列。通过fromIterator()方法实例化新的Labeled数据集对象时,数据表的最最后一列被视为标签。
use Rubix\ML\Datasets\Labeled; use Rubix\ML\Extractors\CSV; use Rubix\ML\Extractors\ColumnPicker; $extractor = new ColumnPicker(new CSV('dataset.csv', true), [ 'MSSubClass', 'MSZoning', 'LotFrontage', 'LotArea', 'Street', 'Alley', 'LotShape', 'LandContour', 'Utilities', 'LotConfig', 'LandSlope', 'Neighborhood', 'Condition1', 'Condition2', 'BldgType', 'HouseStyle', 'OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd', 'RoofStyle', 'RoofMatl', 'Exterior1st', 'Exterior2nd', 'MasVnrType', 'MasVnrArea', 'ExterQual', 'ExterCond', 'Foundation', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinSF1', 'BsmtFinType2', 'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', 'Heating', 'HeatingQC', 'CentralAir', 'Electrical', '1stFlrSF', '2ndFlrSF', 'LowQualFinSF', 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath', 'HalfBath', 'BedroomAbvGr', 'KitchenAbvGr', 'KitchenQual', 'TotRmsAbvGrd', 'Functional', 'Fireplaces', 'FireplaceQu', 'GarageType', 'GarageYrBlt', 'GarageFinish', 'GarageCars', 'GarageArea', 'GarageQual', 'GarageCond', 'PavedDrive', 'WoodDeckSF', 'OpenPorchSF', 'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'PoolQC', 'Fence', 'MiscFeature', 'MiscVal', 'MoSold', 'YrSold', 'SaleType', 'SaleCondition', 'SalePrice', ]); $dataset = Labeled::fromIterator($extractor);
数据集准备
接下来,我们将对训练集应用一系列转换,以便为学习器做好准备。默认情况下,CSV读取器将所有内容导入为字符串 - 因此,我们必须先转换数值为整数和浮点数,以便它们能被学习器识别为连续特征。数值字符串转换器将为我们处理此事。由于一些特征列包含缺失数据,我们还将应用缺失数据填充器,用相当合理的猜测值替换缺失值。最后,由于标签也应该是连续的,我们将使用一个标准的PHP函数intval()回调对标签应用单独的转换,将值转换为整数。
use Rubix\ML\Transformers\NumericStringConverter; use Rubix\ML\Transformers\MissingDataImputer; $dataset->apply(new NumericStringConverter()) ->apply(new MissingDataImputer()) ->transformLabels('intval');
实例化学习器
梯度提升机(GBM)是一种集成估计器,它使用回归树来修复基本学习器的错误。它通过迭代过程来完成,这个过程涉及在先前估计器给出的预测误差残差上训练新的回归树(称为提升器)。因此,GBM产生一个加性模型,其预测结果随着提升器数量的增加而变得更加精细。多个估计器的协调以作为单个估计器是称为集成学习。
接下来,我们将通过实例化梯度提升并将其包裹在一个持久模型元估计器中,以便我们可以在另一个过程中的稍后时间保存它进行预测。
use Rubix\ML\PersistentModel; use Rubix\ML\Regressors\GradientBoost; use Rubix\ML\Regressors\RegressionTree; use Rubix\ML\Persisters\Filesystem; $estimator = new PersistentModel( new GradientBoost(new RegressionTree(4), 0.1), new Filesystem('housing.rbx', true) );
梯度提升的前两个超参数分别是提升器的设置和学习率。对于这个例子,我们将使用最大深度为4的标准回归树作为提升器,学习率为0.1,但您也可以在自己的设置上尝试这些参数。
持久模型元估计器的构造函数将GBM实例作为第一个参数,将持久化对象作为第二个参数。负责在磁盘上存储和加载模型的文件系统持久化器将模型文件的路径作为参数。此外,我们将告诉持久化器为每个保存的模型保留一个副本,通过设置历史模式为true。
设置日志记录器
由于梯度提升实现了详细接口,我们可以在学习器上设置一个记录器实例来监控其训练过程中的进度。内置的屏幕记录器在大多数情况下都能很好地工作,但您也可以使用任何PSR-3兼容的记录器,包括Monolog。
use Rubix\ML\Other\Loggers\Screen; $estimator->setLogger(new Screen());
训练
现在,我们准备好通过调用带训练数据集作为参数的train()方法来训练学习器。
$estimator->train($dataset);
验证分数和损失
在训练过程中,学习器将在每次迭代或周期记录验证分数和训练损失。验证分数是使用默认的RMSE指标在一个保留的训练集部分上计算的。相反,训练损失是计算在训练数据上的代价函数(在这种情况下是L2或二次损失)的值。我们可以通过绘制这些指标来可视化训练进度。要输出分数和损失,您可以在学习器实例上调用额外的steps()方法。然后,我们可以将steps()返回的迭代器导出到CSV文件。
use Rubix\ML\Extractors\CSV; $extractor = new CSV('progress.csv', true); $extractor->export($estimator->steps());
以下是绘制验证分数和训练损失时的示例。您可以通过将progress.csv文件导入您最喜欢的绘图软件来绘制这些值。
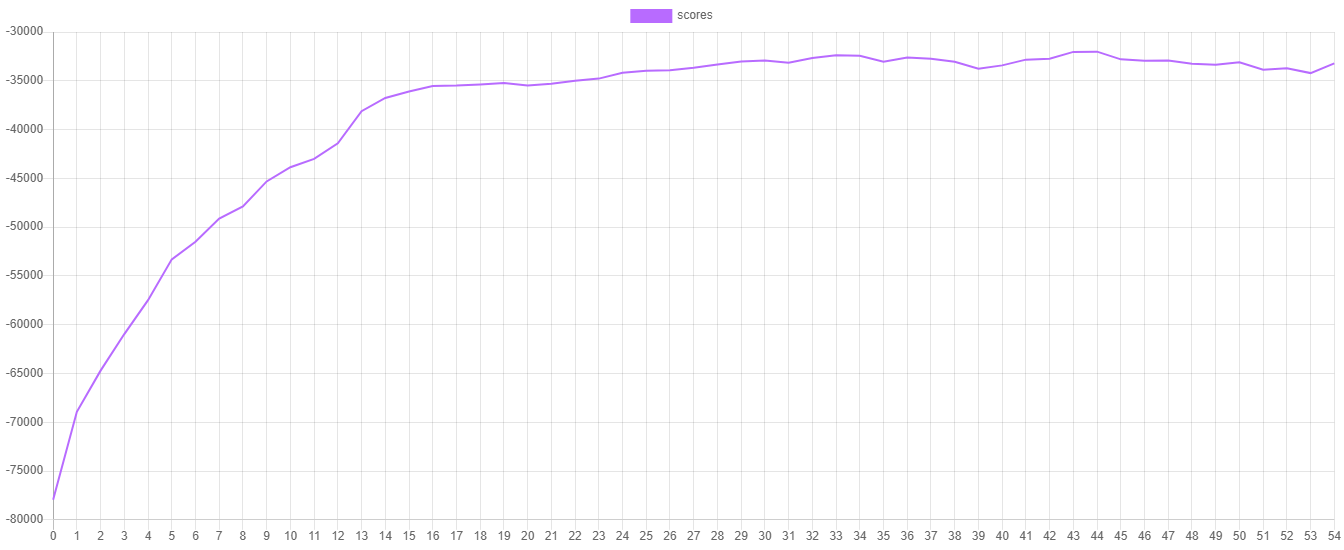
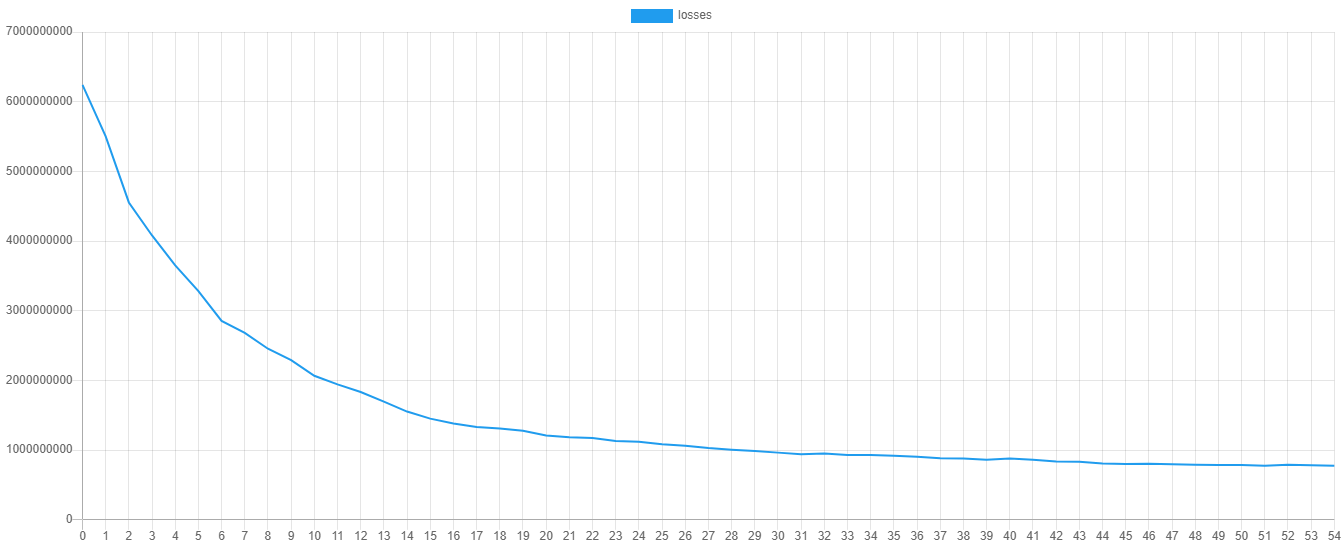
保存
最后,保存模型以便以后可以用它来预测未知样本的房价。
$estimator->save();
现在我们准备好通过在命令行中调用它来执行训练脚本。
$ php train.php
推理
Kaggle竞赛的目标是根据未知样本列表预测每个房子的正确销售价格。如果训练过程中一切顺利,我们只需使用这个基本示例就应能取得良好的结果。我们将从unknown.csv文件中导入未标记的样本。
注意:此示例的源代码可在项目根目录中的predict.php文件中找到。
use Rubix\ML\Datasets\Unlabeled; use Rubix\ML\Extractors\CSV; use Rubix\ML\Transformers\NumericStringConverter; $dataset = Unlabeled::fromIterator(new CSV('unknown.csv', true)) ->apply(new NumericStringConverter());
从存储中加载模型
现在,让我们使用Persistent Model类的静态load()方法将持久化的梯度提升估计器加载到脚本中,通过传递一个指向存储中模型的持久化程序实例。
use Rubix\ML\PersistentModel; use Rubix\ML\Persisters\Filesystem; $estimator = PersistentModel::load(new Filesystem('housing.model'));
做出预测
要获得模型的预测,请使用包含未知样本的数据集调用predict()方法。
$predictions = $estimator->predict($dataset);
然后,我们将使用CSV提取器将ID和预测导出到一个我们将提交给比赛的文件中。
use Rubix\ML\Extractors\ColumnPicker; use Rubix\ML\Extractors\CSV; $extractor = new ColumnPicker(new CSV('dataset.csv', true), ['Id']); $ids = array_column(iterator_to_array($extractor), 'Id'); array_unshift($ids, 'Id'); array_unshift($predictions, 'SalePrice'); $extractor = new CSV('predictions.csv'); $extractor->export(array_transpose([$ids, $predictions]));
现在,通过从命令行调用它来运行预测脚本。
$ php predict.php
做得好!现在您可以将您的预测及其ID提交到竞赛页面,看看您的表现如何。
总结
- 回归器是一种预测连续值结果(如房价)的估计器类型。
- 集成学习将多个估计器的预测组合成一个。
- 梯度提升是一种集成学习器,它使用回归树来修复一个弱基本估计器的错误。
- 默认情况下,梯度提升可以同时处理分类和连续数据类型。
- 数据科学竞赛是练习您的机器学习技能的绝佳方式。
下一步
请查看梯度提升文档页面,以更好地了解学习器能做什么。尝试调整超参数以获得更好的结果。考虑通过数据集对象上的方法过滤掉噪声样本。例如,您可能希望从训练集中删除极端大型且昂贵的房屋。
参考文献
- D. De Cock. (2011). 爱荷华州艾姆斯:作为学期末回归项目的波士顿住房数据替代方案。统计学教育杂志,第19卷,第3期。
许可
代码遵循MIT许可证,教程遵循CC BY-NC 4.0许可证。