rubix / colors
展示使用K均值算法和合成颜色数据进行的无监督聚类。
Requires
- php: >=7.4
- rubix/ml: ^2.0
README
K均值算法是一种流行的无监督学习聚类样本的算法。在本教程中,我们将生成一个合成颜色数据集,以便演示K均值如何将它们聚类成组。
- 难度:简单
- 训练时间:少于一分钟
安装
使用 Composer 在本地克隆项目
$ composer create-project rubix/colors
要求
- PHP 7.4 或更高版本
教程
介绍
在机器学习中,合成数据通常用于演示目的或为了用更多的训练样本来补充较小的数据集。在本教程中,我们将使用合成数据来训练和测试一个 K均值 聚类器,通过颜色对样本进行分组。K均值是一种高度可扩展的算法,它通过为训练集中的每个 k 个聚类找到中心向量(称为 质心)来工作。在推理过程中,测量未知样本到每个质心的距离,以确定它所属的聚类。
注意:本示例的源代码可在项目根目录下的 train.php 文件中找到。
生成数据
Rubix ML 提供了许多数据集 生成器,它们输出特定形状和维度的数据集。对于本示例项目,我们将使用红色、绿色和蓝色(RGB)值作为特征生成颜色通道数据的 Blob。聚合 将将单个颜色生成器合并并标记,形成一个包含所有 10 种颜色且权重相等的 标记 数据集。
use Rubix\ML\Datasets\Generators\Agglomerate; use Rubix\ML\Datasets\Generators\Blob; $generator = new Agglomerate([ 'red' => new Blob([255, 0, 0], 20.0), 'orange' => new Blob([255, 128, 0], 10.0), 'yellow' => new Blob([255, 255, 0], 10.0), 'green' => new Blob([0, 128, 0], 20.0), 'blue' => new Blob([0, 0, 255], 20.0), 'aqua' => new Blob([0, 255, 255], 10.0), 'purple' => new Blob([128, 0, 255], 10.0), 'pink' => new Blob([255, 0, 255], 10.0), 'magenta' => new Blob([255, 0, 128], 10.0), 'black' => new Blob([0, 0, 0], 10.0), ]);
要生成数据集,请使用要生成的样本数(n)作为参数调用 generate() 方法。返回值是一个 数据集 对象,如果需要,您可以使用其方法流畅地处理数据。例如,我们可以将数据集分层并分割成训练集和测试集,使得每个子集包含数据集的比例,并且每种颜色在每个子集中都有公平的代表性。训练集(左侧)与测试集(右侧)中样本的比例由 stratifiedSplit() 方法的 ratio 参数给出。对于本示例,我们将选择生成一组 5,000 个样本,并将其分割为 80/20(4,000 个用于训练和 1,000 个用于测试)。
[$training, $testing] = $generator->generate(5000)->stratifiedSplit(0.8);
现在,让我们使用一些绘图软件,如 Plotly,来看看我们生成的数据。您会注意到每种颜色在三维空间中形成一个独特的 Blob。

实例化学习者
接下来,我们将通过定义其超参数来实例化我们的K均值聚类器。K均值是一种快速在线聚类算法,它使用小批量梯度下降来最小化惯性成本函数。该算法找到一个包含k个聚类质心或目标聚类的多元均值的集合。目标聚类的数量(k)作为超参数传递给学习者构造函数。对于本例,我们已经知道聚类数量应该是10,因此我们将k设置为10。
use Rubix\ML\Clusterers\KMeans; $estimator = new KMeans(10);
训练
一旦实例化了学习者,就使用我们之前生成的训练集作为参数调用train()方法。
$estimator->train($training);
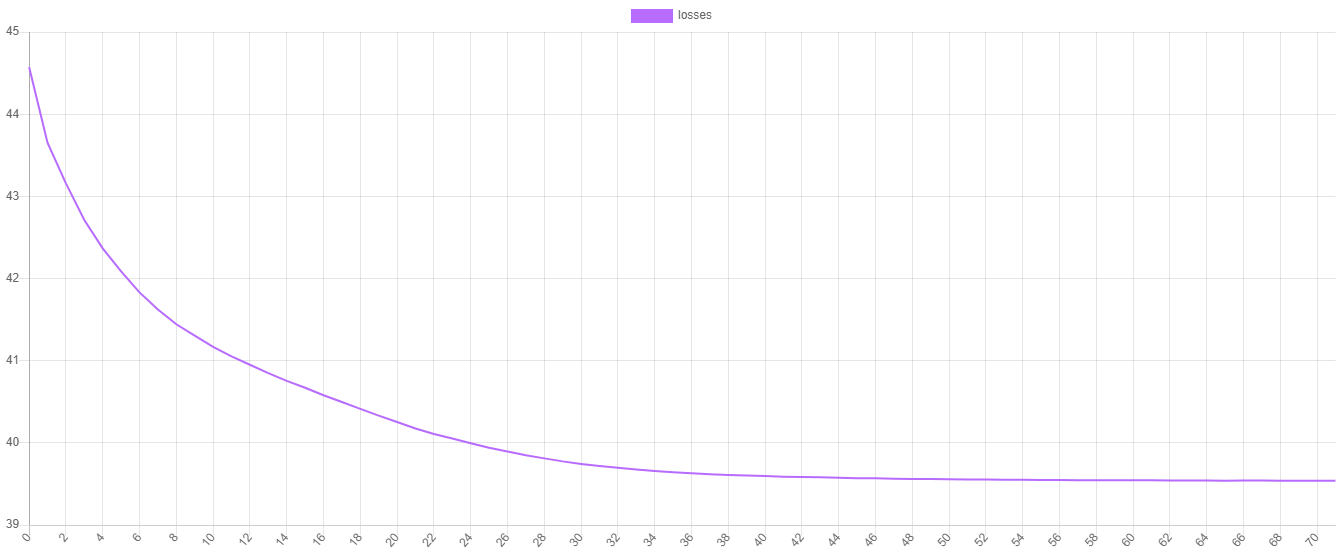
训练损失
K均值使用惯性成本函数来衡量k个质心中每一个的拟合度。我们可以通过在每个epoch绘制成本函数的值来可视化训练进度。要获得训练损失,可以在估计器上调用steps()方法。要将进度保存到文件,可以将steps()方法返回的迭代器传递给可写入提取器的export()方法。
use Rubix\ML\Extractors\CSV; $extractor = new CSV('progress.csv', true); $extractor->export($estimator->steps());
现在,我们可以使用我们喜欢的绘图软件来绘制这些值。如您所见,成本函数的值在每个epoch都会下降,直到K均值满足其停止条件时停止。
进行预测
要做出预测,将测试集传递给估计器实例上的predict()方法。
$predictions = $estimator->predict($testing);
交叉验证
最后,为了测试我们刚刚创建的模型,让我们生成一个交叉验证报告,该报告将预测与标签给出的某些地面真实情况进行比较。一个列联表是一个与混淆矩阵类似的聚类报告,但是用于聚类而不是分类。它计算特定聚类被分配给给定标签的次数。一个好的聚类具有每个聚类包含大致相同标签的样本的列联表。我们需要使用报告的generate()方法之前生成的预测以及测试集的标签。
use Rubix\ML\CrossValidation\Reports\ContingencyTable; $report = new ContingencyTable(); $results = $report->generate($predictions, $testing->labels());
现在我们可以从命令行运行训练和验证脚本。
$ php train.php
以下是列联表的摘录。您会注意到在红色聚类中有一个错误的洋红色点。不错,做得好!
{
"8": {
"red": 100,
"orange": 0,
"yellow": 0,
"green": 0,
"blue": 0,
"aqua": 0,
"purple": 0,
"pink": 0,
"magenta": 1,
"black": 0
},
}
注意:由于K均值算法的随机性质,每次聚类都会略有不同。如果特定的聚类表现不佳,您可以尝试重新训练学习者。
下一步
恭喜您完成了K均值和合成数据生成教程。尝试使用圆形或半月形生成器生成其他形状的数据。K均值能否检测到不同形状和大小的聚类?
许可
代码遵循MIT许可,教程遵循CC BY-NC 4.0许可。