rubix / cifar-10
使用著名的 CIFAR-10 数据集来训练多层神经网络以识别猫、狗和其他物品的图像。
Requires
- php: >=7.4
- ext-gd: *
- rubix/ml: ^1.0
README
CIFAR-10(简称加拿大高级研究研究所)是一个著名的数据集,包含10类(狗、猫、汽车、船只等)的60,000个32 x 32彩色图像,每类有6,000个图像。在本教程中,我们将使用 CIFAR-10 数据集来训练一个前馈神经网络以识别图像中的主要物体。
- 难度:困难
- 训练时间:数小时
安装
使用Composer在本地克隆项目
$ composer create-project rubix/cifar-10
注意:由于数据集较大,安装可能需要比平常更长的时间。
要求
推荐
- Tensor扩展以实现更快的训练和推理
- 10G或更多的系统内存
教程
简介
计算机视觉是深度学习最迷人的用例之一,因为它允许计算机看到我们生活的世界。深度学习是机器学习的一个子集,它通过分层计算将原始数据分解成高级特征表示。神经网络是一种受人类神经系统启发的深度学习模型,它使用称为“隐藏”层的结构化计算单元。在图像识别的情况下,隐藏层能够将图像分解为其组成部分,以便网络可以通过最终输出层的特征特征轻松地理解物体之间的相似性和差异性。让我们开始吧!
提取数据
CIFAR-10数据集以60,000个32 x 32像素PNG图像文件的形式提供,我们将使用GD扩展提供的imagecreatefrompng()将它们导入项目。如果您尚未安装扩展,需要在运行项目脚本之前进行安装。我们还使用preg_replace()从train文件夹中图像的文件名中提取标签。
$samples = $labels = []; foreach (glob('train/*.png') as $file) { $samples[] = [imagecreatefrompng($file)]; $labels[] = preg_replace('/[0-9]+_(.*).png/', '$1', basename($file)); }
现在,将提取的样本和标签加载到一个Labeled数据集对象中。
use Rubix\ML\Datasets\Labeled; $dataset = new Labeled($samples, $labels);
数据集准备
在前一步中导入的图像最终需要转换为连续特征的样本。一个Image Resizer确保所有图像具有相同的维度。一个Image Vectorizer处理从图像中提取红、绿、蓝(RGB)强度(0-255)。最后,一个Z Scale Standardizer将向量化颜色通道数据缩放到均值为0,标准差为1。这一最后步骤有助于网络更快地收敛。我们将这3个转换器封装在一个Pipeline中,以便在保存模型后,我们可以在另一个过程中再次使用它们。
实例化学习器
多层感知器(Multilayer Perceptron)分类器是我们将在 CIFAR-10 数据集中训练的神经网络模型之一。在内部,它使用带有反向传播的梯度下降来学习网络的权重,通过逐渐更新每个神经元对输入产生的信号来更新网络的权重。神经网络的关键方面之一是使用执行中间计算的隐藏层。在 Dense 神经层之间,我们使用一个 Activation 层来执行用户定义的激活函数的非线性变换。激活层引入的非线性对于在数据中学习复杂模式至关重要。在本教程中,我们将使用 ELU 激活函数,这是一个很好的默认选择,但您也可以自由地尝试不同的激活函数。
将学习器和转换器管道包装在一个 Persistent Model 元估计器中,允许我们保存模型,以便我们可以在另一个过程中使用它进行预测。
use Rubix\ML\PersistentModel; use Rubix\ML\Pipeline; use Rubix\ML\Transformers\ImageResizer; use Rubix\ML\Transformers\ImageVectorizer; use Rubix\ML\Transformers\ZScaleStandardizer; use Rubix\ML\Classifiers\MultilayerPerceptron; use Rubix\ML\NeuralNet\Layers\Dense; use Rubix\ML\NeuralNet\Layers\Activation; use Rubix\ML\NeuralNet\Layers\Dropout; use Rubix\ML\NeuralNet\Layers\BatchNorm; use Rubix\ML\NeuralNet\ActivationFunctions\ELU; use Rubix\ML\NeuralNet\Optimizers\Adam; use Rubix\ML\Persisters\Filesystem; $estimator = new PersistentModel( new Pipeline([ new ImageResizer(32, 32), new ImageVectorizer(), new ZScaleStandardizer(), ], new MultilayerPerceptron([ new Dense(200), new Activation(new ELU()), new Dropout(0.5), new Dense(200), new Activation(new ELU()), new Dropout(0.5), new Dense(100, 0.0, false), new BatchNorm(), new Activation(new ELU()), new Dense(100), new Activation(new ELU()), new Dense(50), new Activation(new ELU()), ], 256, new Adam(0.0005))), new Filesystem('cifar10.rbx', true) );
除了隐藏层之外,我们还需要设置 MLP 的几个超参数。批量大小 参数是指在一段时间内将通过网络发送的样本数量。我们将将其设置为 512。接下来,控制学习算法更新步骤的梯度下降优化器和 学习率 将分别设置为 Adam 和 0.001。您可以自由地尝试这些设置。
训练
现在,将训练数据集传递给 train() 方法以开始训练网络。
$estimator->train($dataset);
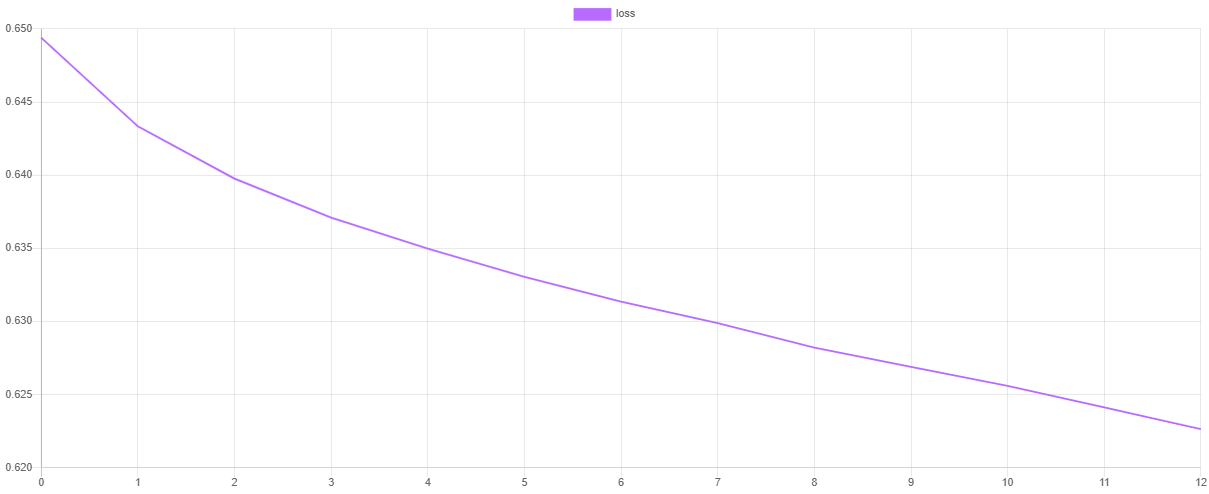
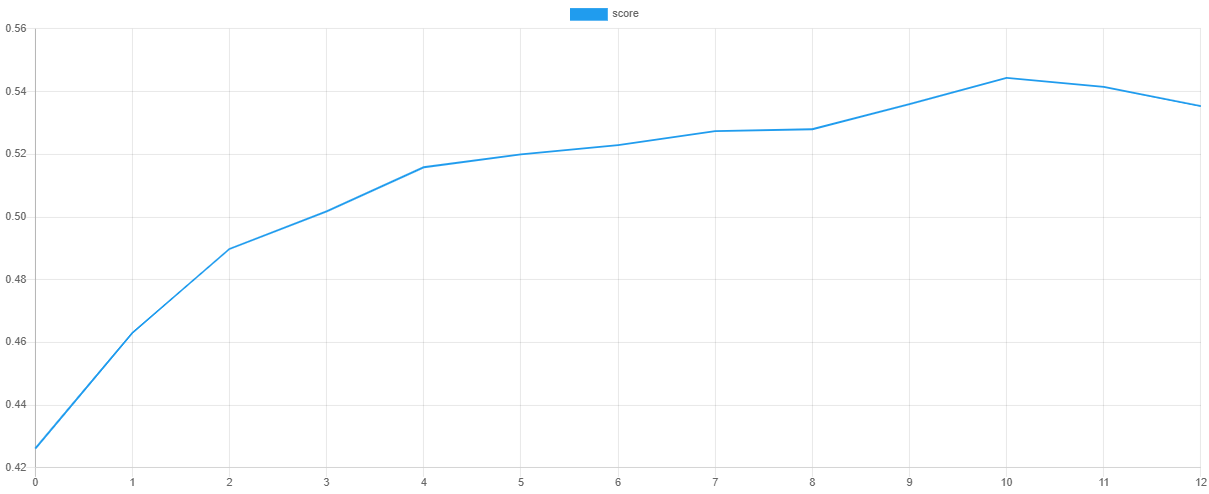
验证分数和损失
我们可以通过在训练后导出损失函数和验证指标的值来可视化每个阶段的训练进度。steps() 方法将输出一个包含默认 交叉熵 成本函数和验证分数的迭代器,这些分数来自默认的 F Beta 指标。
注意:您可以通过将它们设置为学习器的超参数来更改成本函数和验证指标。
use Rubix\ML\Extractors\CSV; $extractor = new CSV('progress.csv', true); $extractor->export($estimator->steps());
然后,我们可以使用我们最喜欢的绘图软件,如 Tableau 或 Excel,来绘制这些值。如果一切顺利,损失值应该随着验证分数的增加而下降。由于快照,验证分数最高和损失最低的时期是网络参数值被取的点。
保存
在退出脚本之前,保存模型,以便我们可以在另一个过程中对其进行交叉验证。
$estimator->save();
现在我们可以从命令行执行训练脚本。
$ php train.php
交叉验证
交叉验证是使用学习者以前从未见过的样本测试模型的过程。目标是能够检测出选择偏差或过拟合等问题。除了训练集,CIFAR-10数据集还包括10,000个测试样本,我们将使用这些样本来评估模型的泛化能力。我们首先使用之前的技术导入位于test文件夹中的测试样本和标签。
$samples = $labels = []; foreach (glob('test/*.png') as $file) { $samples[] = [imagecreatefrompng($file)]; $labels[] = preg_replace('/[0-9]+_(.*).png/', '$1', basename($file)); }
使用测试样本和标签实例化一个Labeled数据集对象。
use Rubix\ML\Datasets\Labeled; $dataset = new Labeled($samples, $labels);
从存储中加载模型
由于我们在上一节训练后保存了模型,因此我们可以在需要将其用于其他进程时随时加载它。Persistent Model类的静态load()方法接受一个指向存储中模型位置的预配置Persister对象,作为其唯一参数,并返回最后已知保存状态的包装估计器。
use Rubix\ML\PersistentModel; use Rubix\ML\Persisters\Filesystem; $estimator = PersistentModel::load(new Filesystem('cifar10.rbx'));
进行预测
我们需要MLP在测试集上产生的预测结果,以及将真实类别标签传递给报告生成器。要将预测结果作为数组返回,请将测试集传递给估计器的predict()方法。
$predictions = $estimator->predict($dataset);
生成报告
多类别分解和混淆矩阵是交叉验证报告,它们显示了模型在每个类别上的性能。我们将它们都封装在汇总报告中,并将测试集中的预测结果以及真实标签传递给generate()方法,以同时生成两个报告。
use Rubix\ML\CrossValidation\Reports\AggregateReport; use Rubix\ML\CrossValidation\Reports\ConfusionMatrix; use Rubix\ML\CrossValidation\Reports\MulticlassBreakdown; $report = new AggregateReport([ new MulticlassBreakdown(), new ConfusionMatrix(), ]); $results = $report->generate($predictions, $dataset->labels());
要运行验证脚本,请在命令提示符中输入以下命令。
$ php validate.php
查看结果以了解模型在推理上的表现。以下是多类别分解报告的摘录,显示了整体性能。如图所示,模型在识别图像中的对象方面做得相当不错,但仍有改进的空间。
"overall": { "accuracy": 0.8538682791748626, "precision": 0.5467567594653738, "recall": 0.5372000000000001, "specificity": 0.9134813190242806, "negative_predictive_value": 0.9138360056175517, "false_discovery_rate": 0.4532432405346262, "miss_rate": 0.46280000000000004, "fall_out": 0.08651868097571924, "false_omission_rate": 0.08616399438244826, "f1_score": 0.5322032931908443, "mcc": 0.4528826530026047, "informedness": 0.4506813190242807, "markedness": 0.46059276508292557, "true_positives": 5372, "true_negatives": 48348, "false_positives": 4628, "false_negatives": 4628, "cardinality": 10000, "density": 1 },
混淆矩阵的摘录显示,估计器在识别汽车方面做得很好,但有时会将它们误认为是卡车,这在很多方面是有道理的。
"automobile": { "cat": 14, "dog": 6, "airplane": 14, "ship": 37, "deer": 4, "automobile": 603, "frog": 9, "horse": 10, "bird": 12, "truck": 130 },
下一步
祝贺您使用Rubix ML完成CIFAR-10教程!现在是时候自己尝试其他网络架构、激活函数和学习率了。尝试向网络中添加额外的隐藏层以加深网络并增加模型的灵活性。全连接网络是这个问题最好的架构吗?是否有其他网络架构可以利用图像的空间信息?
原始数据集
创建者:Alex Krizhevsky 邮箱:akrizhevsky '@' gmail.com
参考
- [1] A. Krizhevsky. (2009). Learning Multiple Layers of Features from Tiny Images.
许可证
代码遵循MIT许可证,教程遵循CC BY-NC 4.0许可证。