rubix / churn
Requires
- php: >=7.4
- rubix/ml: ^2.3
This package is auto-updated.
Last update: 2024-08-29 06:18:09 UTC
README
机器学习是从传统编程范式转变的一种范式,因为它允许软件本身通过训练和数据来修改其编程。因此,您可以将其视为“用数据编程”。将机器学习集成到您的项目中是将开发者编写的逻辑与机器学习算法学到的逻辑合并的实践。今天,我们将讨论如何使用开源的Rubix ML库开始将机器学习模型集成到您的PHP项目中。我们将制定客户流失预测的问题,训练一个模型来识别不满意的客户是什么样的,然后使用该模型检测我们数据库中的不满意的客户。
- 难度: 中等
- 训练时间: 秒
安装
使用 Composer 在本地克隆项目
$ composer create-project rubix/churn
要求
- PHP 7.4 或更高版本
教程
简介
让我们从介绍预测客户流失的问题开始。流失率是指在一段时间内,客户停止使用产品或服务的比率。如果我们能够预测哪些客户最有可能离开,那么我们就可以在他们离开之前采取行动来修复关系。但是,我们作为开发者如何编码规则集,即确定不满意的客户是什么样的“业务逻辑”呢?
想象一下,你是一家电信公司的开发者,负责优化客户流失。你可以做的一件事是询问客服部门客户对服务的看法。你可能会了解到,住在某个地区的客户更容易抱怨网速慢并停止服务。你也可能会了解到,老年客户对流媒体电视和电影的选择非常满意,因此更有可能保留他们的订阅。你 可以 通过手动编码这些规则开始,但当你考虑所有影响客户满意度的不同因素时,这会迅速变得难以应对。相反,我们可以将满意和不满意的客户样本通过学习算法进行输入,并让学习器自动学习规则。然后,我们可以使用该模型来对我们数据库中的客户做出预测。
准备数据集
在训练模型之前,我们需要收集满意和不满意的客户样本,并对其进行相应标记。然后,我们将确定哪些客户特征有助于确定客户是否会流失。例如,服务区域和客户寻求技术支持的电话次数可能是数据集中应包括的好特征,但如眼睛颜色和客户是否有后院等特征可能包括它们反而会适得其反。在下面的示例中,我们将使用CSV提取器加载提供的示例数据集的样本,然后使用ColumnPicker选择特征子集。在Rubix ML中,提取器是迭代器,可以从存储中将数据流式传输到内存中,并可以由其他迭代器包装以修改流中的数据。请注意,我们将每个样本的标签作为数据表的最后一列包括在内,这是惯例。
use Rubix\ML\Extractors\CSV; use Rubix\ML\Extractors\ColumnPicker; $extractor = new ColumnPicker(new CSV('dataset.csv', true), [ 'Gender', 'SeniorCitizen', 'Partner', 'Dependents', 'MonthsInService', 'Phone', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'TV', 'Movies', 'Contract', 'PaperlessBilling', 'PaymentMethod', 'MonthlyCharges', 'TotalCharges', 'Region', 'Churn', ]);
在Rubix ML中,数据集对象提供了一组高级API,允许您处理样本并创建子集等。接下来,我们将通过将提取器对象传递给静态方法fromIterator()来实例化一个标记的数据集对象。
use Rubix\ML\Datasets\Labeled; $dataset = Labeled::fromIterator($extractor);
接下来,我们将创建数据集的两个子集,用于训练和测试。训练集将由朴素贝叶斯用于学习模型,测试集将在训练后用于评估模型的准确性。在创建子集之前对样本进行随机化可以帮助减少数据收集方法引入的潜在偏差。通过标签对样本进行分层确保两个子集中类别的比例保持不变。在下面的示例中,我们将80%的标记样本放入训练集,并使用剩余的20%进行后续的验证,使用随机分层拆分方法。
注意:我们使用不同的样本来训练模型和验证模型的原因是我们想要在学习者从未见过的样本上测试学习器。
[$training, $testing] = $dataset->randomize()->stratifiedSplit(0.8);
模型训练
朴素贝叶斯是一种使用计数和贝叶斯定理来推导给定仅包含分类特征的样本的标签条件概率的算法。术语“朴素”指的是算法的特征独立性假设。它之所以被称为“朴素”,是因为在现实世界中,大多数特征都有相互作用。然而,在实践中,这种假设并没有造成太大的问题。
为了实例化我们的朴素贝叶斯估计器,我们需要调用构造函数并传递一组参数(称为“超参数”),这些参数将控制学习者的行为。朴素贝叶斯的当前实现有两个我们需要注意的超参数。priors参数允许用户指定类先验概率(即随机选择时特定类别将成为结果的概率),而不是默认从训练集中计算先验概率。例如,如果我们知道在现实世界中我们的平均流失率约为5%,则可以将其指定为"Yes"类的先验概率,朴素贝叶斯将据此做出预测。第二个超参数是平滑参数,它控制训练过程中计算的每个特征的条件概率中添加的拉普拉斯平滑量。平滑是一种正则化形式,可以防止模型过于自信,尤其是在训练样本数量较低时。在本例中,我们将smoothing参数设置为默认值1.0,但您可以在自己的实验中尝试这些设置,看看它们如何影响模型的准确性。
use Rubix\ML\Classifiers\NaiveBayes; $estimator = new NaiveBayes([ "Yes" => 0.05, "No" => 0.95, ]);
在示例数据集中,MonthsInService、MonthlyCharges和TotalCharges特征都具有数值。由于默认情况下,所有CSV格式的值都被解释为字符串,因此我们需要应用一个预处理步骤,将数据集中的数值字符串(例如,“42”)转换为它们的整数和浮点表示。为此,我们将在第一个预处理步骤中应用一个无状态的转换器Numeric String Converter,以将所有值转换为整数值。然而,由于朴素贝叶斯仅与分类特征兼容,因此我们将在下一个步骤中应用Interval Discretizer,从上述数值特征中推导出3个离散类别。在MonthsInService的上下文中,您可以将其视为将月份数转换为三个等比例的水平之一 - “短”、“中”或“长”。
我们将整个转换系列以及朴素贝叶斯估计器包装在一个管道元估计器中,以便在训练或推理之前自动拟合和预处理数据集。拟合转换器类似于训练学习器,通过包装转换器和估计器,我们可以将转换器拟合以及模型参数作为一个原子对象保存。
use Rubix\ML\Pipeline; use Rubix\ML\Transformers\NumericStringConverter; use Rubix\ML\Transformers\IntervalDiscretizer; $estimator = new Pipeline([ new NumericStringConverter(), new IntervalDiscretizer(3, true), ], $estimator);
现在我们准备好通过将训练数据集传递给新实例化的管道元估计器来拟合转换器并训练模型。
$estimator->train($training);
我们可以通过在估计器接口上调用trained()方法来验证学习器是否已经训练。
var_dump($estimator->trained());
bool(true)
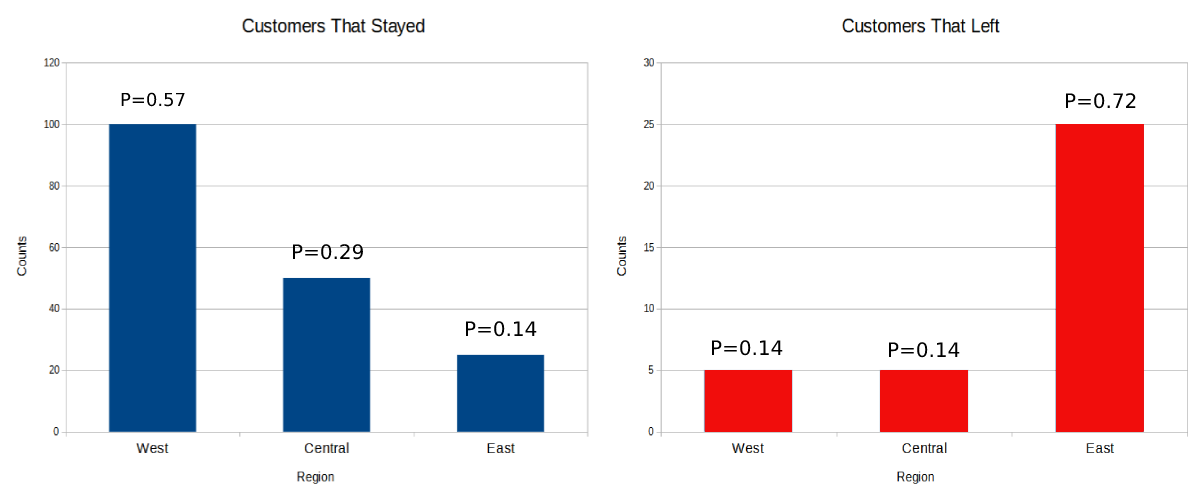
为了更好地理解调用train()方法时发生了什么,让我们简要地看看朴素贝叶斯算法的内部结构。算法首先为特定类结果构建每个特征的直方图,通过计算类别在训练数据中出现的次数。然后,算法通过除以样本大小来计算直方图中每个类别的条件概率。算法对数据集中的每个分类特征重复此过程。稍后,我们将演示如何将这些条件概率结合起来产生类结果的总体概率。在下面的例子中,我们看到的是Region特征的直方图。注意,在东部地区提供服务的客户比其他地区的客户更有可能流失。
制作测试预测
为了在处理过程中的验证步骤生成一些测试预测,我们需要进行预测操作。在机器学习术语中,这一操作被称为“推理”,因为它涉及到对一个未标记样本进行推断以确定其标签。在训练后,通过将测试数据集传递给估计器上的predict()方法,我们可以返回一组预测。
$predictions = $estimator->predict($testing);
我们可以通过像下面的例子那样将类预测输出到终端来查看。
print_r($predictions);
Array
(
[0] => No
[1] => No
[2] => No
[3] => Yes
[4] => No
)
在内部,朴素贝叶斯算法将先验概率与每个可能类别的未知样本的条件概率相结合,然后预测后验概率最高的类别。以下公式表示朴素贝叶斯用于进行类预测的决策函数,其中p(Ck)是类先验概率,在本例中作为一个超参数给出,而p(xi | Ck)是类Ck在特征xi上的条件概率,这是在训练期间计算的。
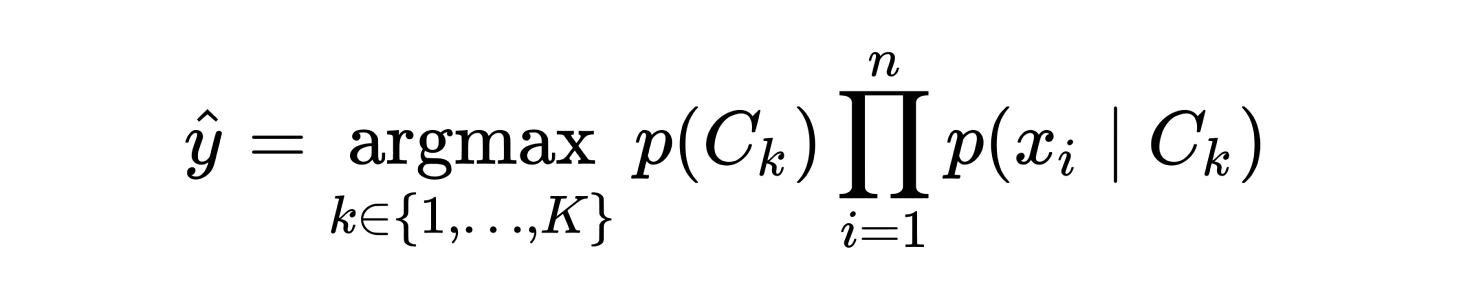
尽管这个公式准确地表示了朴素贝叶斯的高层次决策函数,但在Rubix ML中的实际计算是在对数空间中完成的。由于非常低的概率在相乘时往往会变得不稳定,因此对数概率提供了更大的数值稳定性,通过将原始公式中的乘积转换为加和。
验证模型
有了测试预测及其真实标签,我们现在可以集中精力使用“保留法”来验证模型。我们用来确定泛化性能的过程被称为交叉验证,而保留法是最简单直接的方法之一。这个方法的优点是快速,只需要训练一个模型就可以产生一个有意义的验证分数。然而,这个技术的缺点是,由于模型验证分数仅从样本的一部分计算得出,所以它的覆盖范围不如训练多个模型并在每次测试时使用不同样本的方法。在下一个例子中,我们将从保留的测试数据中生成一个报告,其中包含我们评估模型准确性的详细指标。
我们将实例化一个多类别分解和混淆矩阵报告生成器,并将它们封装在一个汇总报告中,以便它们可以同时生成。多类别分解是一个详细的报告,包含了准确率、精确率、召回率、F-1分数等多个指标的分数,以及基于整体和每个类别的详细信息。混淆矩阵是一个表格,将一个轴上的预测计数与另一个轴上的真实计数配对。计数每一对可以让我们对估计器可能“混淆”其他类别的哪些类别有一个概念。
use Rubix\ML\CrossValidation\Reports\AggregateReport; use Rubix\ML\CrossValidation\Reports\ConfusionMatrix; use Rubix\ML\CrossValidation\Reports\MulticlassBreakdown; $reportGenerator = new AggregateReport([ new MulticlassBreakdown(), new ConfusionMatrix(), ]);
要创建报告对象,请调用报告生成器的generate()方法,并将我们从测试集生成的预测和真实标签作为参数传递。
$report = $reportGenerator->generate($predictions, $testing->labels());
由于报告对象实现了Stringable接口,我们可以直接将报告输出到终端。下面的示例展示了这个分类器和数据集的典型报告。您会注意到朴素贝叶斯在区分流失客户方面做得相当不错,准确率约为78%。
echo $report
[
{
"overall": {
"accuracy": 0.7806955287437899,
"balanced accuracy": 0.7405835852127411,
"f1 score": 0.7301102604109521,
"precision": 0.7226865136298422,
"recall": 0.7405835852127411,
"specificity": 0.7405835852127411,
"negative predictive value": 0.7226865136298422,
"false discovery rate": 0.27731348637015785,
"miss rate": 0.2594164147872588,
"fall out": 0.2594164147872588,
"false omission rate": 0.27731348637015785,
"mcc": 0.4629242695197278,
"informedness": 0.4811671704254823,
"markedness": 0.4453730272596843,
"true positives": 1100,
"true negatives": 1100,
"false positives": 309,
"false negatives": 309,
"cardinality": 1409
},
"classes": {
"No": {
"accuracy": 0.7806955287437899,
"balanced accuracy": 0.7405835852127411,
"f1 score": 0.8469539375928679,
"precision": 0.8689024390243902,
"recall": 0.8260869565217391,
"specificity": 0.6550802139037433,
"negative predictive value": 0.5764705882352941,
"false discovery rate": 0.13109756097560976,
"miss rate": 0.17391304347826086,
"fall out": 0.34491978609625673,
"false omission rate": 0.42352941176470593,
"informedness": 0.4811671704254823,
"markedness": 0.4453730272596843,
"mcc": 0.4629242695197278,
"true positives": 855,
"true negatives": 245,
"false positives": 129,
"false negatives": 180,
"cardinality": 1035,
"proportion": 0.7345635202271115
},
"Yes": {
"accuracy": 0.7806955287437899,
"balanced accuracy": 0.7405835852127411,
"f1 score": 0.6132665832290363,
"precision": 0.5764705882352941,
"recall": 0.6550802139037433,
"specificity": 0.8260869565217391,
"negative predictive value": 0.8689024390243902,
"false discovery rate": 0.42352941176470593,
"miss rate": 0.34491978609625673,
"fall out": 0.17391304347826086,
"false omission rate": 0.13109756097560976,
"informedness": 0.4811671704254823,
"markedness": 0.4453730272596843,
"mcc": 0.4629242695197278,
"true positives": 245,
"true negatives": 855,
"false positives": 180,
"false negatives": 129,
"cardinality": 374,
"proportion": 0.2654364797728886
}
}
},
{
"No": {
"No": 855,
"Yes": 129
},
"Yes": {
"No": 180,
"Yes": 245
}
}
]
我们还可以保存报告以与同事分享或稍后查看。要保存报告,请在报告对象上调用toJSON()方法返回的编码对象上的saveTo()方法。在这个例子中,我们将使用文件系统持久化器将报告保存到名为report.json的文件中。
use Rubix\ML\Persisters\Filesystem; $report->toJSON()->saveTo(new Filesystem('report.json'));
保存模型
我们还将保存流水线估计器,以便我们可以在另一个过程中使用它来预测我们数据库中的客户。Rubix ML提供了一个名为持久化模型的元估计器,它包装了一个持久化估计器,并提供保存和从存储中加载模型参数的方法。在下面的示例中,我们将使用默认的RBX序列化器将我们的流水线对象包装在持久化模型中并将其保存到文件系统中。RBX是一种基于PHP原生序列化并添加了压缩、完整性检查和版本兼容性检测的专有格式。如果您愿意,也可以使用标准的PHP 原生序列化器。
use Rubix\ML\PersistentModel; use Rubix\ML\Persisters\Filesystem; $estimator = new PersistentModel($estimator, new Filesystem('model.rbx')); $estimator->save();
进入生产环境
在实践中,我们可能会花更多时间在训练和交叉验证上,以尝试微调数据集和超参数。在本教程的下一部分,我们将假设我们目前对模型性能感到满意,并准备将其投入生产。
首先,我们需要在实时推理或缓存预测之间做出选择。对于这个问题,同时为所有客户生成预测并将其存储在数据库中与客户数据一起存储是非常有意义的。然后,我们可以通过在应用的后台运行的脚本定期预测新客户并更新现有客户。这种设计的好处是,我们不需要将模型加载到内存中。然而,如果您需要立即获取新客户的预测或如果您有一个快速发展的模型,您可能需要考虑进行实时推理。请参阅Server包,了解如何使用异步PHP和长时间运行的过程以高效的方式执行此操作。
我们将启动一个新脚本,以预测数据库中客户的标签。为了演示,我们提供了一个包含2000多个客户的示例SQLite数据库。让我们从数据库中加载数据样本,并使用我们保存的模型来预测处于风险中的客户。SQL Table提取器是一个迭代器,它遍历整个数据库表。在下一个示例中,我们将引用我们的SQLite数据库的PDO对象传递给SQL Table提取器的构造函数,以及我们想要遍历的表名。
use Rubix\ML\Extractors\SqlTable; use PDO; $connection = new PDO('sqlite:database.sqlite'); $extractor = new SqlTable($connection, 'customers');
如果我们不想在数据库中加载所有客户,我们可以将提取器包裹在标准的PHP Limit Iterator中,以指定偏移量和限制。
$extractor = new LimitIterator($extractor->getIterator(), 0, 100);
就像我们在训练和验证集上所做的那样,我们将实例化一个Column Picker来从数据库中选择特征输入到估计器中。我们还将包括Id列,我们将在稍后更新数据库时使用它。
$extractor = new ColumnPicker($extractor, [ 'Id', 'Gender', 'SeniorCitizen', 'Partner', 'Dependents', 'MonthsInService', 'Phone', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'TV', 'Movies', 'Contract', 'PaperlessBilling', 'PaymentMethod', 'MonthlyCharges', 'TotalCharges', 'Region', ]);
现在,通过将提取器作为参数调用fromIterator()方法,实例化一个未标记的数据集对象。
$dataset = Unlabeled::fromIterator($extractor);
要为数据集中的每个样本返回客户ID,请调用带有列偏移量为0的feature()方法。通过从数据集中删除它来避免将客户ID馈送到估计器。
$ids = $dataset->feature(0); $dataset->dropFeature(0);
我们几乎完成了!现在,通过在Persistent Model meta-Estimator类上调用load()方法,将我们之前保存的Pipeline估计器加载到内存中,其中使用一个指向存储中模型文件路径的文件系统持久化器作为参数。请注意,如果您没有使用默认序列化器,您可能需要提供选项序列化器。一旦从存储中加载,估计器将以保存时的相同状态准备好。
$estimator = PersistentModel::load(new Filesystem('model.rbx'));
最后,通过将推理集传递给Pipeline meta-Estimator上的predict()方法,返回数据库中客户的预测。预测将按照我们从数据库加载的样本的相同顺序返回。
$predictions = $estimator->predict($dataset);
我们将使用之前相同的PDO连接对象准备一个SQL语句来更新客户。从这里,我们可以遍历预测并更新数据库中相应的行。
$statement = $connection->prepare("UPDATE customers SET churn=? WHERE id=?"); foreach ($predictions as $i => $prediction) { $statement->execute([$prediction, $ids[$i]]); }
太棒了!您已经确定了可能面临流失风险的客户。让我们花点时间回顾一下。记得我们加载了一个由客户服务部门标记为流失或未流失的训练数据集。然后我们使用该数据集来训练一个朴素贝叶斯分类器,以预测数据库中客户的流失率。最后,我们将这些预测存储在数据库中,以便我们可以在应用中稍后使用。干得好!为了进一步学习,您可能想考虑...
- 使用特征的不同子集进行训练。是否有一些特征比其他特征更有预测性?
- 不同的先验概率和光滑超参数如何影响预测?
- 将朴素贝叶斯替换为与分类特征兼容的其他分类器,例如随机森林或Logit Boost。
原始数据集
https://github.com/codebrain001/customer-churn-prediction
许可证
代码遵循MIT许可证,教程遵循CC BY-NC 4.0许可证。