通过以下链接搜索 
peteujah / broken-links-scanner
一个用于扫描网站以识别断链并提取相关信息的PHP库。
1.0.0
2024-09-21 16:17 UTC
Requires
- php: ^7.0
- ext-curl: *
Suggests
- ext-curl: Required for performing HTTP requests when scanning websites.
README
一个用于扫描网站以识别断链并提取相关信息的PHP库。请确保已安装所需的PHP扩展,尤其是 cURL,以便扫描器能正常工作。
通过Composer安装非常简单
composer require peterujah/broken-links-scanner
CLI用法
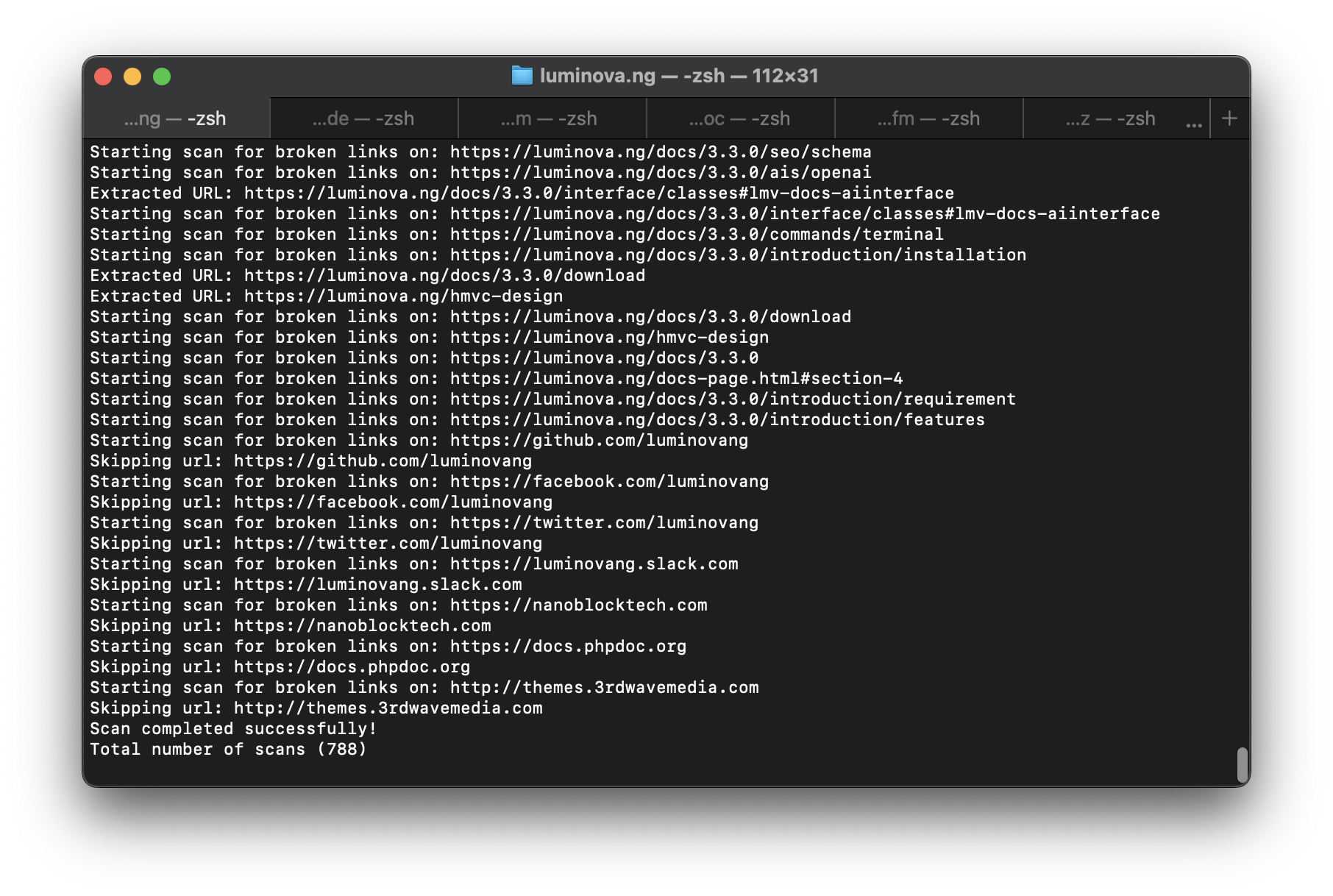 使用CLI脚本扫描网站的断链。
使用CLI脚本扫描网站的断链。
选项
--url(必需):扫描的起始URL(例如,http://luminova.ng/docs/或http://luminova.ng/)。--host(必需):扫描URL的主机名(例如,luminova.ng)。--path(可选):保存扫描结果的路径。--output(可选):控制断链输出的标志。使用1打印,或0禁止输出(默认:0)。--timeout(可选):等待扫描完成的秒数(默认:0)。--limit(可选):要执行的扫描的最大次数。使用0扫描所有URL(默认:0)。
示例用法
要开始扫描,请运行以下命令
php broken --url="https://luminova.ng/" --host="luminova.ng" [--timeout=10] [--path="/scanner/logs"] [--output=0] [--limit=0]
示例:使用扫描器扫描网站的断链
使用必要的参数初始化 Scanner 并注册您的自定义类。
1. 基本用法
require_once __DIR__ . '/vendor/autoload.php'; use \Peterujah\BrokenLinks\Scanner; // Define the starting URL for the scan $url = 'https://luminova.ng/'; $host = 'luminova.ng'; $maxScan = 10; // Set to 0 to scan all URLs. // Initialize the BrokenLinks class $scanner = new Scanner($url, $host, $maxScan); // Optionally set the path to save scanned URLs $scanner->setPath($path);
2. 开始扫描并获取结果
如果未设置路径,您可以直接获取输出
if ($scanner->start() && $scanner->isCompleted()) { // Get results from the scan $brokenLinks = $scanner->getBrokenLinks(); $visitedUrls = $scanner->getVisitedUrls(); $errors = $scanner->getErrors(); $allUrls = $scanner->getUrls(); // Output the scanned data echo "Broken Links:\n"; print_r($brokenLinks); echo "\nVisited URLs:\n"; print_r($visitedUrls); echo "\nErrors Encountered:\n"; print_r($errors); echo "\nAll Extracted URLs:\n"; print_r($allUrls); } else { echo "Failed to complete the scan.\n"; }
3. 使用 wait 方法
要等待扫描完成,您可以使用指定超时的 wait 方法
$timeout = 30; try { $scanner->wait($timeout, function (BrokenLinks $scanner) { $brokenLinks = $scanner->getBrokenLinks(); echo "Broken Links:\n"; print_r($brokenLinks); }); } catch (RuntimeException $e) { echo "Error: " . $e->getMessage() . "\n"; }
注意:使用
wait方法时,无需再次调用start方法。
类方法文档
__construct
- 描述:使用指定的URL和主机名初始化扫描器的新实例。
- 参数
string $url:扫描的起始URL(例如,https://luminova.ng/docs/)。string $host:要扫描的URL的主机名(例如,luminova.ng)。int $maxScan:要执行的扫描的最大次数(默认为0,表示无限制)。
isCompleted(): bool
- 描述:检查扫描过程是否已完成。
- 返回
bool:如果扫描已完成,则返回true;否则,返回false。
getBrokenLinks(): array
- 描述:检索扫描期间识别的断链列表。
- 返回
array:包含断链的数组。
getVisitedUrls(): array
- 描述:检索扫描期间访问的URL列表。
- 返回
array:包含访问URL的数组。
getErrors(): array
- 描述:检索扫描过程中遇到的错误消息。
- 返回
array:包含错误消息的数组。
getUrls(): array
- 描述:检索扫描期间提取的URL列表。
- 返回
array:包含提取URL的数组。
setPath(string $path): self
- 描述:设置扫描URL将保存的文件路径。
- 参数
string $path:保存扫描URL的文件路径。
- 返回
self: 返回当前类的实例,以便进行方法链式调用。
cli(bool $cli): self
- 描述:设置是否在命令行界面(CLI)中显示扫描结果。
- 参数
bool $cli:true表示在 CLI 模式下运行;否则,false。
- 返回
self: 返回当前类的实例,以便进行方法链式调用。
start(): bool
- 描述:启动链接扫描过程。
- 返回
bool: 如果扫描成功完成,则返回true;否则返回false。
- 抛出异常
RuntimeException: 如果提供的 URL 无效,则抛出异常。
wait(int $timeout, ?callable $onComplete = null): void
- 描述:等待扫描过程完成或直到达到指定的超时时间。如果提供了回调函数,则在完成时执行它。
- 参数
int $timeout: 最大等待秒数。如果0,则无限期等待,直到扫描完成。callable|null $onComplete: 可选的回调函数,在扫描完成时执行。
- 抛出异常
RuntimeException: 如果在完成之前超时,则抛出异常。