manofstrong / sitescrapper
一个用于从网站地图中抓取网站并从网页中提取相关内容的包,然后将内容上传到数据库以供以后使用的软件包
Requires
- php: >= 7.0
- catfan/medoo: ^1.6
- donatello-za/rake-php-plus: ^1.0
- fabpot/goutte: ^3.2
- sters/extract-content: ^0.0.3
- sunra/php-simple-html-dom-parser: ^1.5
- vipnytt/sitemapparser: ^1.0
Requires (Dev)
This package is auto-updated.
Last update: 2024-09-14 00:00:13 UTC
README
一个基于网站地图抓取网站并从网页中提取相关内容的PHP库,提取的内容随后上传到数据库以供后续使用。
Sitemaps.org 协议是领先的标准,由 Google、Bing、Yahoo、Ask 等许多公司支持,并已成为显示网站中网页及其相关性的标准方式。这意味着大多数现代网站都实施了网站地图,这使得网站抓取器更容易避免不必要的步骤来查找链接,并直接访问源。请注意,该库可以递归地解析网站地图,因此每个网站只需要一个网站地图。
此库还通过移除样板内容并提取其余内容为全文来消除探索特定于网站的 HTML 标签以查找相关内容的需要。然后,该库获取提取文本的关键词和文本的单词数。这些对于后续数据分析和关键词至关重要。最后,该库将内容上传到 MySQL 数据库,其模式已包含在本项目的数据库文件夹中。
基本上,这是一个盲目的大规模抓取工具,只需提供网站地图列表,运行它即可。它将运行直到抓取完提供的网站页面并将它们上传到数据库。
此库旨在从命令行运行,而不是从网页浏览器运行。请将其视为 CLI 工具并相应地使用。
特性
- 网站地图解析(单个网站或网站列表)
- 抓取(相关内容提取)
- 关键词提取
- 提取数据的单词数
- 自定义 User-Agent 字符串
- 将提取内容上传到数据库
支持的网站地图格式
- XML
.xml - 压缩 XML
.xml.gz - Robots.txt 规则表
robots.txt
支持的网页格式
- HTML
text/html
支持的网站地图文件格式
- 文本
text/txt
安装
该库可通过 Composer 安装。只需将其添加到您的 composer.json 文件中
{
"require": {
"manofstrong/sitescrapper": "^0.0.1"
}
}
然后运行 composer update。
入门
基本显示示例
返回单个网站地图中指定数量的页面内容。不存储到数据库中。
<?php require 'vendor/autoload.php'; use Manofstrong\sitescrapper; $scrapeThisSite = new SiteScrapper(); $singleSitemapUrl = 'https://www.php.com/sitemap.xml'; // can be .xml or .xml.gz or robots.txt file $numberOfPages = 2; // must be a digit without single or double quotation marks: '2' or "2" will fail. $scrapeThisSite -> showContentSiteMap($singleSitemapUrl, $numberOfPages);
此命令以数组形式显示每个页面的内容,包括以下四个元素:url、标题、关键词、内容和单词数,如以下图像所示
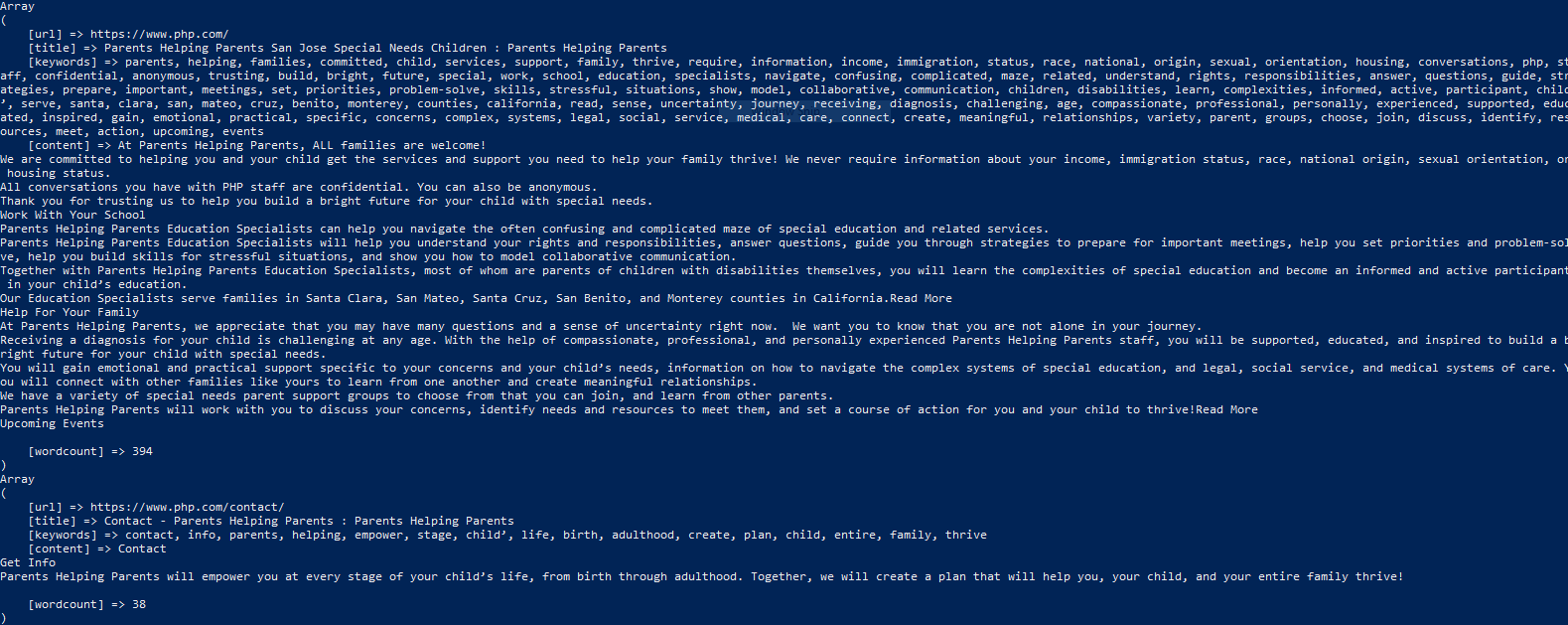
单个网站地图
从单个网站地图中提取网页的方法。这将遍历网站并更新提供的数据库。它将返回 URL 和完成状态。
<?php require 'vendor/autoload.php'; use Manofstrong\sitescrapper; $scrapeThisSite = new SiteScrapper(); $singleSitemapUrl = 'https://www.php.com/sitemap.xml'; // MySQL table structure in the database folder of this repository $scrapeThisSite -> databaseCredentials('database','host','username','password'); $scrapeThisSite -> singleSiteMap($singleSitemapUrl);
网站地图数组
从数组中提供的网站地图提取网页的方法。这将遍历数组中的网站,并更新提供的数据库。它将返回 URL 和完成状态。如果您想抓取的网站少于 10 个,建议使用此方法。
<?php require 'vendor/autoload.php'; use Manofstrong\sitescrapper; $scrapeThisSite = new SiteScrapper(); $sitemapArray = ['https://site1.com/sitemap.xml','https://site2.com/sitemap.xml','https://site3.com/sitemap.xml']; // MySQL table structure in the database folder of this repository $scrapeThisSite -> databaseCredentials('database','host','username','password'); $scrapeThisSite -> siteMapsArray($sitemapArray);
网站地图文件
从通过数组提供的站点地图中提取网页的方法。这将遍历文件中的所有站点,并更新提供的数据库。它将返回URL和完成状态。如果您想要抓取10个以上的不同网站,这将是推荐的。
文件必须是一个文本文件,并且每个站点地图必须独占一行,行内不能有其他文本。URL也必须符合[RFC 2396](https://www.ietf.org/rfc/rfc2396.txt)。
对于不符合规范的站点地图URL,库将创建一个名为skippedurls.txt的文件,并将它们列在那里。您可以随后查看此文件,进行必要的更正以确保符合规范。
<?php require 'vendor/autoload.php'; use Manofstrong\sitescrapper; $scrapeThisSite = new SiteScrapper(); $sitemapFile = __DIR__ . '/yourtextfile.txt'; // MySQL table structure in the database folder of this repository $scrapeThisSite -> databaseCredentials('database','host','username','password'); $scrapeThisSite -> siteMapFile($sitemapFile);
示例文件结构
https://site1.com/sitemap.xml
https://site2.com/sitemap.xml
http://site3.com/sitemap.xml
https://site4.com/sitemap.xml
https://site5.com/sitemap.xml
https://site6.com/sitemap.xml
https://site7.com/sitemap.xml
https://site8.com/sitemap.xml
https://site9.com/sitemap.xml
https://site10.com/sitemap.xml
https://www.site11.com/sitemap.xml
https://www.site12.com/sitemap.xml
http://www.site13.com/sitemap.xml
https://www.site14.com/sitemap.xml
https://www.site15.com/sitemap.xml
https://www.site16.com/sitemap.xml
https://www.site17.com/sitemap.xml
https://www.site18.com/sitemap.xml
https://www.site19.com/sitemap.xml
https://www.site20.com/sitemap.xml
http://site21.com/sitemap.xml
用户代理的高级设置
注意:默认用户代理是ManofStrong SiteScrapper Tool v1.0 (+https://github.com/manofstrong/sitescrapper/)
如果您想更改并使用自己的用户代理,请使用此方法。
<?php require 'vendor/autoload.php'; use Manofstrong\sitescrapper; $scrapeThisSite = new SiteScrapper(); $scrapeThisSite -> setUserAgent('Example User Agent. For Text Data Data Assigment.');
许可证
SiteScrapper遵循MIT许可证。
限制
这不是一个精确的数据收集工具,尤其是对于想要获取网页特定部分而排除其他部分的用户来说。这个库仅仅收集网页最重要的部分,如大块文本。因此,这个库最适合那些以大量文本数据收集和提取为目标的人,用于大数据或其他分析研究。
使用提示
如果您在远程服务器上运行此代码,并且已经通过ssh连接,请在Screen中运行它以避免中断。关于Linux Screen命令的更多信息,请参阅这里。